
Over the past few years, language models have emerged as a fundamental component of artificial intelligence, significantly advancing various natural language processing tasks. Transformer-based models, in particular, have achieved top-notch performance in language comprehension and generation. However, these models face challenges in terms of efficiency and memory usage, particularly when working with lengthier sequences.
Limitations of Transformer Architecture :
- Increased memory use and slower speeds: This fundamental issue affects the scalability and practical application of Transformer architectures, particularly when simultaneously handling lengthy documents or multiple tasks.
- High memory needs and issues with subword tokenization: These limitations significantly impact the efficiency and accuracy of models, which are crucial for a wide range of applications, from language processing to content generation.
- Inefficiency in handling long-distance relationships in text: This affects the core capability of Transformer models to process long sequences accurately, directly impacting performance in tasks requiring understanding of context over large spans of text.
- Occasional large drops in performance during training: Instabilities during training can impede the development and fine-tuning of large models, resulting in decreased performance and reliability.
- Complex preprocessing requirements and tokenization biases: These issues challenge the model’s language independence and fairness, which are critical for broad, real-world applications across diverse linguistic contexts.
- Significant computational resources required for visual tasks: This limits the applicability of Transformer architectures in computer vision, a field with growing demand for advanced, efficient models.
Jamba is a new hybrid language model that addresses these challenges by combining the strengths of Transformer layers, Mamba layers, and Mixture-of-Experts (MoE).
What is Jamba
Jamba introduces a hybrid architecture integrating Transformer layers, Mamba layers, and Mixture-of-Experts (MoE). This unique combination aims to improve performance and efficiency while maintaining a manageable memory footprint. By leveraging the strengths of each component, Jamba can handle complex language tasks with remarkable accuracy and speed..
How Jamba Works
Interleaving Transformer and Mamba Layers
At the core of Jamba’s architecture is the interleaving of Transformer and Mamba layers. This strategic combination allows the model to leverage the strengths of both architectures, resulting in improved performance and efficiency.
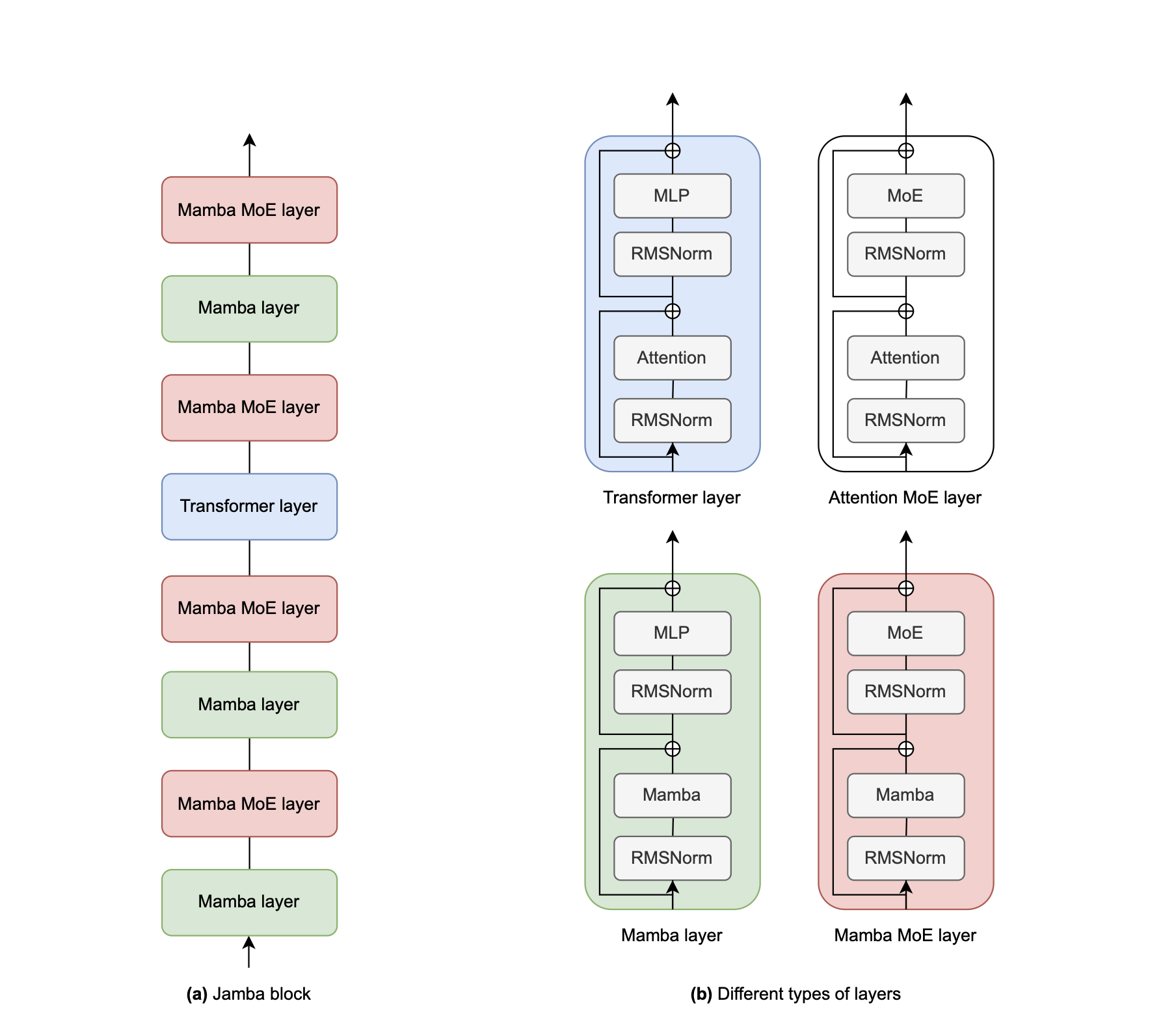
- Transformer layers are known for their ability to capture complex patterns and long-distance relationships within input sequences. They achieve this through the self-attention mechanism, which computes a weighted sum of all positions in the input sequence for each position. This allows the model to attend to relevant information from different parts of the input when generating outputs. Transformer layers are particularly effective in capturing contextual information and modeling dependencies between distant tokens.
- On the other hand, Mamba layers are designed to be compute-efficient when processing long sequences. As state-space models, they maintain a summary of the input sequence in a hidden state, which is updated at each step. This allows Mamba layers to process sequences in a linear fashion without the quadratic complexity of self-attention. By efficiently compressing the input sequence into a hidden state, Mamba layers can handle long contexts with reduced computational overhead.
Jamba alternates between Transformer and Mamba layers, creating a powerful hybrid architecture. The Transformer layers capture rich contextual information and long-range dependencies, while the Mamba layers provide computationally efficient processing of long sequences. This interleaving strategy allows Jamba to strike a balance between modeling complex patterns and maintaining efficiency.
Mixture-of-Experts (MoE)
Jamba incorporates Mixture-of-Experts (MoE) layers to increase the model’s capacity without significantly increasing computational requirements. MoE is a technique that introduces multiple expert networks within a layer, each specializing in different aspects of the task.

- In an MoE layer, the input is first processed by a gating mechanism, which determines the assignment of each token to the available experts. The gating mechanism learns to route tokens to the most appropriate experts based on their content and position. This allows the model to efficiently utilize its capacity by directing tokens to specialized experts.
- Each expert network in an MoE layer is a separate neural network that specializes in processing specific types of input. For example, one expert may focus on syntactic information, while another may specialize in semantic relationships. By having multiple experts, the model can capture a wide range of patterns and learn more nuanced representations.
- The outputs from the selected experts are then combined using a weighted sum, where the weights are determined by the gating mechanism. This aggregation step allows the model to integrate the specialized knowledge from different experts and produce a final output.
The use of MoE layers in Jamba enables efficient scaling of the model’s capacity. By increasing the number of experts, Jamba can expand its representational power without a proportional increase in computational cost. This is because only a subset of the experts is activated for each input token, reducing the effective computational burden.
Resource and Objective-Specific Configurations
One of the key strengths of Jamba is its flexible architecture, which allows for resource and objective-specific configurations. Users can tailor the model to their specific needs by adjusting various hyperparameters and architectural choices.
- For example, the ratio of Transformer to Mamba layers can be adapted based on the characteristics of the task and the available computational resources. If the task requires capturing long-range dependencies and complex patterns, a higher proportion of Transformer layers can be used. On the other hand, if efficiency is a primary concern and the task involves processing very long sequences, a higher ratio of Mamba layers can be employed.
- Similarly, the number and placement of MoE layers can be customized to strike a balance between model capacity and computational cost. By strategically inserting MoE layers at different depths in the network, Jamba can allocate its capacity to the most critical parts of the model.
- Other hyperparameters, such as the hidden state size, number of attention heads, and feed-forward dimensions, can also be adjusted to match the requirements of the task and the available resources. This flexibility allows Jamba to be deployed in various scenarios, from resource-constrained environments to large-scale applications.
- For example, in a mobile device with limited memory and processing power, Jamba can be configured with a higher ratio of Mamba layers and fewer MoE layers to minimize the memory footprint and computational cost. On the other hand, for a cloud-based application with ample resources, Jamba can be configured with a higher proportion of Transformer layers and more MoE layers to maximize performance.
Key Components of Jamba
Transformer Layers
Transformer layers form a crucial component of Jamba’s hybrid architecture. These layers are based on the Transformer model, which has revolutionized natural language processing in recent years. Transformer layers are designed to capture complex patterns and long-distance relationships within input sequences.

- At the heart of the Transformer layer is the self-attention mechanism. Self-attention allows the model to weigh the importance of different parts of the input sequence when generating outputs. It computes a weighted sum of the input representations, where the weights are determined by the similarity between each pair of positions in the sequence.
- The self-attention mechanism operates on three matrices: the query, key, and value matrices. The query matrix represents the current position being processed, while the key and value matrices represent all positions in the input sequence. The attention weights are computed by taking the dot product of the query matrix with the key matrix, followed by a softmax function to normalize the weights.
- The attention weights are then used to compute a weighted sum of the value matrix, resulting in a new representation of the current position. This process is repeated for all positions in the sequence, allowing the model to capture dependencies and relationships between different parts of the input.
- Transformer layers also include feed-forward neural networks and layer normalization to further process the representations and stabilize training. The feed-forward networks apply non-linear transformations to the attention outputs, enabling the model to learn more complex patterns.
By stacking multiple Transformer layers, Jamba can capture hierarchical representations and model intricate relationships within the input sequences. The self-attention mechanism allows information to flow between distant positions, enabling the model to capture long-range dependencies effectively.
Mamba Layers
Mamba layers are a key component of Jamba’s hybrid architecture, designed to efficiently process long sequences while addressing the limitations of traditional Transformer models. Developed to enhance sequence modeling, Mamba utilizes Structured State Space sequences (S4) to combine the strengths of various modeling approaches, enabling efficient modeling of long-term dependencies. This makes Mamba particularly well-suited for tasks involving lengthy data sequences.

- At the heart of Mamba’s architecture lies the Selective-State-Spaces (SSM) mechanism, a recurrent model that selectively processes information based on the current input. By focusing on relevant information and discarding the irrelevant, SSM streamlines computation and improves inference speed. This simplicity is achieved by replacing the complex attention and Multilayer perceptron (MLP) blocks found in Transformers with a unified SSM block, aiming to reduce computational complexity and enhance overall performance.
- Mamba’s architecture is explicitly designed to leverage contemporary hardware capabilities, optimizing memory usage and parallel processing to maximize GPU computing power. This design philosophy results in reduced data transmission times and faster processing, setting a new performance benchmark for sequence models. Mamba’s ability to process lengthy sequences more quickly and simply than Transformers is particularly evident, showcasing its efficiency and scalability.
- Another key feature of Mamba is its ability to make faster inference possible by scaling linearly with sequence length. This offers a new paradigm in sequence modeling that becomes increasingly effective as sequences grow longer. By efficiently handling long-term dependencies and reducing computational complexity, Mamba has the potential to drive the next wave of AI innovations across various industries.
The integration of Mamba layers into Jamba’s hybrid architecture brings together the strengths of Transformers and state-space models, resulting in a powerful and efficient language model. By leveraging Mamba’s selective processing and linear scaling capabilities, Jamba can tackle tasks involving long sequences with unprecedented speed and simplicity, opening up new possibilities for natural language processing and beyond.
Mixture-of-Experts (MoE)
Mixture-of-Experts (MoE) layers are another critical component of Jamba that enables efficient scaling of the model’s capacity. MoE layers introduce multiple expert networks within a single layer, each specializing in different aspects of the task.

- In an MoE layer, the input tokens are first processed by a gating mechanism, which determines the assignment of each token to the available experts. The gating mechanism is typically implemented as a softmax function that produces a probability distribution over the experts for each token. The token is then routed to the experts with the highest probabilities.
- Each expert network in an MoE layer is a separate neural network specializing in processing specific input types. Depending on the task’s specific requirements, these expert networks can have different architectures, such as feed-forward networks or attention-based models. The model can capture a wide range of patterns and learn specialized representations by having multiple experts.
- The outputs from the selected experts are then combined using a weighted sum, where the weights are determined by the gating mechanism. This aggregation step allows the model to integrate the specialized knowledge from different experts and produce a final output.
MoE layers offer several advantages in terms of model capacity and computational efficiency. By increasing the number of experts, Jamba can expand its representational power without a proportional increase in computational cost. This is because only a subset of the experts is activated for each input token, reducing the effective computational burden.
Furthermore, MoE layers enable efficient parallelization during training and inference. Since each expert network can process its assigned tokens independently, the computation can be distributed across multiple devices or cores, leading to faster processing times.
The use of MoE layers in Jamba allows for flexible scaling of the model’s capacity based on the available resources and the complexity of the task. By adjusting the number of experts and the gating mechanism, Jamba can adapt to different scenarios and optimize its performance.
Significance of Jamba
Performance on Benchmarks Jamba has demonstrated exceptional performance on a wide range of standard language model benchmarks.

Jamba has performed excellently on various benchmarks. Its success is attributed to its hybrid architecture, which combines the strengths of Transformer layers, Mamba layers, and MoE. By interleaving these components, Jamba is able to model long-range dependencies, capture hierarchical representations, and efficiently process long sequences.
Long-Context Evaluations
One of Jamba’s standout features is its excellence in handling long context lengths. Jamba supports context lengths up to 256K tokens, significantly higher than most existing large language models. This capability is great for tasks that require processing and understanding extended passages of text, such as document summarization, question answering, and context-aware language generation.
To showcase Jamba’s long-context capabilities, researchers evaluated its performance on the “Needle-in-a-haystack” problem, which tests a model’s ability to retain and utilize information from a long context.
In this problem, a single piece of relevant information (the “needle“) is hidden within a large amount of irrelevant text (the “haystack“), and the model must accurately retrieve the “needle” when prompted.

Jamba achieves a high retrieval accuracy of over 90% for context lengths up to 256K tokens, demonstrating its ability to locate and retrieve relevant information even when buried within vast amounts of irrelevant text. Jamba’s strong performance is due to its hybrid architecture, which combines the Transformer and Mamba layers.
The “Needle-in-a-haystack” evaluation highlights the potential of Jamba to revolutionize tasks that require processing and understanding of lengthy documents, such as legal document analysis, medical record processing, and financial report generation. By efficiently capturing and utilizing crucial information from extended contexts, Jamba opens up new possibilities for advanced language understanding and generation tasks in real-world applications where relevant information may be sparse and hidden within large volumes of text.
Efficiency and Resource Usage
Another significant aspect of Jamba is its impressive efficiency and resource usage. Jamba demonstrates a 3x throughput compared to similar models when processing long contexts. This means that Jamba can process three times more data in the same amount of time, leading to faster training and inference times.
The efficiency of Jamba is particularly notable considering its ability to handle long context lengths. Despite supporting contexts up to 256K tokens, Jamba maintains high throughput, enabling faster processing of extended passages of text. This is crucial for applications that require real-time or near-real-time processing, such as online language translation or interactive conversational systems.
In terms of resource usage, Jamba has a remarkably small memory footprint. The model can fit in a single 80GB GPU even when handling contexts over 128K tokens. This memory efficiency is achieved through the use of Mamba layers, which compress the input sequence into a compact hidden state representation. By reducing the memory requirements, Jamba can be deployed on a wider range of hardware, including resource-constrained devices.
The efficiency and resource usage of Jamba have significant implications for the deployment of language models in real-world scenarios. With faster processing times and lower memory requirements, Jamba can be integrated into various applications, from mobile devices to large-scale cloud services. This makes Jamba more accessible and practical for a wide range of users and industries.
Furthermore, Jamba’s efficiency translates into cost savings and reduced environmental impact. Jamba can help organizations minimize their computational costs and carbon footprint by processing more data with fewer resources. This is particularly important as the demand for language modeling capabilities continues to grow across different domains.
Future Directions and Potential Extensions
Decoupled Routing in Self-Attention
One potential area of exploration for Jamba is the investigation of decoupled routing in the self-attention mechanism. Currently, in the Transformer layers of Jamba, the self-attention mechanism computes attention weights based on the similarity between the query, key, and value matrices. These matrices are derived from the same input representations.
- Decoupled routing in self-attention involves separating the computation of attention weights for the query, key, and value matrices. This allows for more fine-grained control over the token participation in the attention computation. By decoupling the routing, different subsets of tokens can be used for the query, key, and value matrices, enabling more specialized and targeted attention.
- Investigating decoupled routing in self-attention could potentially lead to improved performance and efficiency in Jamba. By allowing the model to selectively attend to different parts of the input sequence for each component of the attention mechanism, Jamba could capture more nuanced relationships and generate more precise outputs.
However, keep in mind that decoupled routing also introduces additional complexity and computational overhead. Balancing the benefits and challenges of this approach would require careful experimentation and analysis. Further research could explore different strategies for decoupling the routing, such as using separate learned projections for the query, key, and value matrices or employing different attention mechanisms for each component.
Integration of Specialized Computations
Jamba’s hybrid architecture provides a solid foundation for integrating specialized computations to enhance its capabilities for specific tasks. One promising direction is the incorporation of memory lookup mechanisms within Jamba. Memory lookup allows the model to access and retrieve relevant information from an external knowledge base or memory component during the processing of input sequences.
By integrating memory lookup, Jamba could effectively combine its language understanding capabilities with external knowledge sources. This would enable Jamba to perform tasks that require access to factual information, such as question answering, knowledge-based inference, and entity-aware language generation. The memory component could store structured or unstructured data, such as knowledge graphs, databases, or text snippets, which Jamba could query and retrieve based on the input context.
Combination with Optimization Techniques
While Jamba already demonstrates impressive efficiency and performance, there is potential to further optimize the model through the combination of various optimization techniques. Pruning, quantization, and knowledge distillation are three prominent techniques that could be explored to improve Jamba’s efficiency and resource usage.
Pruning is a technique that involves removing less important weights or connections from the model, thereby reducing its size and computational requirements. Pruning can be applied to Jamba by identifying and removing weights that have minimal impact on the model’s performance. This can be done through various pruning strategies, such as magnitude-based pruning or gradient-based pruning. By pruning redundant or less significant weights, Jamba’s memory footprint and inference time can be reduced without significantly sacrificing performance.
Quantization is another optimization technique that can be applied to Jamba. Quantization involves reducing the precision of the model’s weights and activations, typically from 32-bit floating-point numbers to lower-bit representations, such as 8-bit or 16-bit integers. Quantization can significantly reduce Jamba’s memory usage and computational cost, as lower-precision operations require less storage and can be executed faster on hardware. However, quantization may introduce some accuracy loss, so careful tuning and analysis are necessary to strike the right balance between efficiency and performance.
Knowledge distillation is a technique that aims to transfer knowledge from a large, complex model (the teacher) to a smaller, simpler model (the student). In the context of Jamba, knowledge distillation could be used to create a more compact and efficient version of the model. The larger Jamba model would serve as the teacher, and a smaller student model would be trained to mimic its behavior. By distilling the knowledge from Jamba into a smaller model, the computational cost and memory requirements can be reduced while retaining much of the performance.
Combining these optimization techniques with Jamba’s hybrid architecture could yield significant improvements in efficiency and resource usage. However, it is important to carefully consider the trade-offs between performance and efficiency when applying these techniques. Pruning, quantization, and knowledge distillation should be applied judiciously, taking into account the specific requirements and constraints of the target application.
Balancing performance and resource usage is a key challenge in optimizing Jamba. The goal is to find the right combination of techniques that maximize efficiency while maintaining acceptable levels of accuracy and performance. This may involve iterative experimentation and fine-tuning to find the optimal configuration for each specific use case.
The combination of optimization techniques with Jamba’s hybrid architecture opens up new possibilities for deploying large-scale language models in resource-constrained environments. By reducing the memory footprint and computational requirements, Jamba can be made more accessible and practical for a wider range of devices and applications, from mobile devices to edge computing scenarios.
Ablation Studies and Design Choices
Ablation studies involve systematically removing components from a model or system to understand the contribution of each part to the system’s overall performance. This approach helps to identify which components are essential for the system’s functionality and which are not, thereby providing insights into the system’s behavior and improving its design.
The Jamba model was developed through ablation studies and careful design choices to optimize its performance and efficiency. The researchers experimented with different architectural components and hyperparameters to understand their impact on the model’s behavior.
- One of the significant tests conducted on the hybrid architecture was focused on the proportion of Transformer to Mamba layers. The researchers conducted several experiments using different ratios to determine the ideal balance between modeling power and efficiency. The results showed that a ratio of 1:3 or 1:7 (one Transformer layer for every three or seven Mamba layers) worked best in terms of performance and computational cost. These ratios allowed Jamba to capture complex patterns and long-range dependencies while maintaining high efficiency.
- Another important ablation study investigated the impact of the Mixture-of-Experts (MoE) component on Jamba’s performance. The researchers varied the number of expert networks and the gating mechanism used to route tokens to the experts. They found that increasing the number of experts led to improved performance, as it allowed the model to capture more specialized knowledge. However, they also observed that the gains in performance diminished beyond a certain number of experts, indicating a point of diminishing returns.
- The choice of activation functions and normalization techniques was also carefully considered in the design of Jamba. Based on their experiments, they chose the RMSNorm for the Mamba layers, as these provided the best performance and stability.
- Researchers conducted studies on Jamba’s positional encoding schemes and found that even without explicit positional encodings, Jamba performed well. This suggests that Jamba’s hybrid architecture, with the interleaving of Transformer and Mamba layers, can implicitly capture positional information.
The ablation studies and design choices implemented in the development of Jamba were critical in shaping its final architecture and performance. The researchers carefully analyzed the impact of different components and hyperparameters, making informed decisions based on empirical evidence. As a result, the hybrid architecture with the optimal ratio of Transformer to Mamba layers, the incorporation of MoE, and the choice of activation functions and normalization techniques played a significant role in making Jamba highly efficient and state-of-the-art performance.
Conclusion
In conclusion, Jamba represents a groundbreaking advancement in language modeling, introducing a novel hybrid architecture that combines the strengths of Transformer, Mamba, and Mixture-of-Experts (MoE) components. This innovative approach enables Jamba to achieve state-of-the-art performance across a wide range of natural language processing tasks while maintaining high efficiency and supporting long context lengths. The hybrid architecture, which interleaves Transformer and Mamba layers, allows the model to effectively capture complex patterns, long-range dependencies, and hierarchical representations. Incorporating the MoE component further enhances Jamba’s capacity and flexibility, making it highly adaptable to various resource constraints and performance requirements.
Jamba’s ability to support context lengths up to 256K tokens sets it apart from most existing language models, making it crucial for tasks that involve processing and understanding extended passages of text. The efficiency and flexibility of Jamba’s architecture make it suitable for a wide range of applications and deployment scenarios, demonstrating impressive throughput and a small memory footprint.
To encourage further research and development, the weights of Jamba and checkpoints from ablation runs are being made publicly available under Apache license, encouraging collaboration and knowledge sharing within the research community.
Jamba represents a significant milestone in the evolution of language modeling architectures, showcasing the potential of hybrid approaches that leverage the strengths of different components. Its impact extends beyond immediate performance on benchmarks, contributing to a deeper understanding of the fundamental principles and trade-offs in language modeling. Jamba’s hybrid architecture opens up new possibilities for tackling a wide range of natural language processing applications, particularly those involving long contexts and complex patterns. As the field continues to evolve, Jamba serves as an inspiring example of the impact that architectural innovations can have on advancing the state of the art in natural language processing.
Key Links
Research Paper: Jamba: A Hybrid Transformer-Mamba Language Model
Authors: pher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, Omri Abend, Raz Alon, Tomer Asida, Amir Bergman, Roman Glozman, Michael Gokhman, Avashalom Manevich, Nir Ratner, Noam Rozen, Erez Shwartz, Mor Zusman, Yoav Shoham
AI21 Labs : https://www.ai21.com/jamba




















You must be logged in to post a comment.