A Framework for Decision Rights, Audit Evidence, and Regulatory Readiness in the Age of Agentic AI
Audio Overview
Executive Summary
Enterprise AI has outpaced the governance designed to control it. Models ship before governance teams know they exist. Agents make decisions no one can reconstruct. Decision services run in production without audit trails that would survive a regulator’s questions. The distance between AI’s influence on your business and your ability to explain that influence is growing, not shrinking.
There is a second risk most governance programs miss entirely: the AI you did not build. SaaS products now ship with embedded models. Productivity platforms add copilots without asking. Vendors sell agentic workflows while disclaiming compliance responsibility in the fine print. Governance teams focus on internal models. The real exposure is vendor AI running inside core business processes with no oversight, no audit trail, and contract terms that shift liability to you. A third of major breaches in 2025 involve third parties. Your AI vendors are part of that attack surface.
The regulatory environment has shifted from theoretical discussions to actual enforcement. The EU AI Act’s high-risk provisions will take effect in August 2026, with penalties of up to €35 million or 7% of global revenue. Colorado’s AI Act is set to follow in June 2026. Twenty-four states now require insurance companies to implement written AI governance programs. The FDA has introduced new lifecycle requirements for over 1,250 approved AI medical devices. Boards have observed a significant increase: AI oversight committees have tripled across Fortune 100 firms in the past year.
What regulators are asking for is the architectural evidence on how decisions are made, how models are controlled, how changes are governed, and how incidents can be reconstructed. Governance is shifting from a policy overlay to an infrastructure approach.
In this article, we will treat AI governance as an architecture problem. We will examine the compliance theater that passes for governance today, the vendor supply chain most programs ignore, and the emerging threat surface of agentic AI systems. We will then introduce the CTRS (Control Tower Reasoning System) framework for decision-layer governance, paired with a decision-rights model, an audit-trail architecture, and a 90-day implementation roadmap.
Trust in AI emerges from architecture, not policy. And that architecture must include the AI supply chain you are already running.
I. The Anatomy of Compliance Theater
Ask any enterprise about its AI program, and you will hear an impressive answer. Dozens of models in production. Copilots across business lines. AI-enabled workflows generating real value.
Now ask different questions. How do you know what decisions these systems are making? How would you reconstruct a decision if a regulator asked? Who approved the current model configuration?
The answers get vague fast. That gap between what organizations can demonstrate about AI adoption and what they can prove about AI control is compliance theater.
What Compliance Theater Means
The term comes from security, where “security theater” describes visible measures that provide the appearance of safety without meaningfully reducing risk. Airport shoe removal is the classic example: visible, inconvenient, and largely ineffective.
Compliance theater follows the same pattern. Organizations invest in governance artifacts that look credible to outside observers but do not constrain how AI systems actually behave. The artifacts exist. The control does not.
Walk through any large enterprise, and you will find the symptoms:
- AI ethics principles framed on office walls, but not encoded in any system
- Responsible AI training completed by thousands of employees who never touch model development
- Risk assessments filed at project kickoff and never revisited
- Vendor questionnaires checked “yes” without technical validation
- Model inventories that list systems but not the decisions those systems make
Compliance theater is not an intentional deception but a byproduct that occurs when fast-moving AI deployments meet slow-moving governance machinery. Governance exists on paper while real decisions get made elsewhere, at machine speed, with no one watching.
I.1. The Governance-Assurance Gap

Surveys confirm what the questions reveal. McKinsey’s 2024 State of AI report found that 72% of enterprises have AI systems in production, but only 9% describe their AI governance as mature.
Look at what organizations actually measure, and the gap becomes obvious.
What gets tracked:
- Number of AI projects initiated
- Number of models or AI systems in production
- Number of pilots or proofs of concept
- Training sessions delivered on responsible AI
What does not get tracked:
- Percentage of critical decisions with explainable lineage
- Time to reconstruct a decision for an auditor or regulator
- Coverage of model change management: what changed, why, and who approved it
- Share of AI decisions subject to defined decision rights and override mechanisms
The first list measures activity. The second measures assurance. Most organizations excel at the first and ignore the second. They can talk about AI at the program level, but cannot prove control at the decision level.
I.2. Why Theater Persists
Ask why this gap exists, and you will hear about resource constraints, competing priorities, and the speed of AI adoption. These are fundamental factors. But the deeper answer is the lack of incentives for implementing AI Governance.
CIOs get measured on deployment velocity, not governance maturity. Shipping AI features moves quarterly metrics. Building governance infrastructure does not. When leadership pressure favors speed, governance becomes something to satisfy rather than something to implement.
Talk to governance teams, and a different picture emerges. A three-person AI ethics team cannot review hundreds of model deployments per year. They produce frameworks, policies, and review templates. They cannot be present at every decision point. So they create artifacts and hope those artifacts get followed.
Now look at the cadence mismatch. Boards ask about AI risk once or twice a year. AI systems make decisions every millisecond of every day. By the time a quarterly committee reviews an AI system, that system has made millions of decisions and may have drifted from its original behavior. It may have already caused harm that has not yet surfaced.
Theater becomes rational in this environment. Good-enough governance works until it does not. And when it fails, the cost is high.
I.3. The Cost When Theater Fails
Ask what happens when governance theater meets reality, and the numbers are stark:
- 52% of data breaches now cost over $1 million, up from 38% in 2021
- Average ransomware incident costs $5.5 to $6 million
- EU AI Act penalties reach €35 million or 7% of global turnover for prohibited practices
- 86% of organizations experienced at least one breach in 2024, up from 80% in 2021
These are a few aggregate statistics. If you dive into individual cases, they are more instructive.
Air Canada’s chatbot quoted an updated bereavement policy. The system retrieved accurate information from an outdated source. A tribunal held the airline liable. Ask the governance team what went wrong, and the answer is simple: there was no mechanism to ensure the AI cited only current policies. A corporate policy requiring information to be kept current in their chatbot should have existed. However, it clearly indicates that the enforcement mechanism for this policy was missing.
The Epic Sepsis Model tells a similar story on a larger scale. The model to identify patients at risk of sepsis was deployed across hundreds of hospitals. However, an external validation found that the model missed two-thirds of sepsis cases while generating alerts for 18% of all hospitalized patients. Clinicians described this model as “not only useless but generating additional meaningless work.”
The actual cause of this inconsistency was the model itself, as it was trained to predict when doctors would bill for sepsis treatment rather than recognizing early patient symptoms. A governance system that evaluated the model’s actual behavior rather than its intended purpose would have identified this issue before deployment.
Both failures have a common factor. Governance artifacts were present, but enforcement mechanisms were missing. Policies stated one thing, while systems acted differently. No one detected the discrepancy until the damage had already occurred.
I.4. Policy Documents vs. Enforcement Mechanisms

If you ask to see an organization’s AI governance, they will show you documents like AI principles, responsible AI policies, model risk management standards, and vendor risk questionnaires. Now, ask a different question: where is that policy enforced at runtime? Where does the code prevent what the policy prohibits? The documents are necessary. They are not sufficient.
Policy documents:
- Static, human-readable
- Describe what should happen
- Live in PDFs, intranet pages, policy portals
Enforcement mechanisms:
- Dynamic, machine-enforced
- Constrain what can happen at runtime
- Live in gateways, policy engines, access controls, and monitoring systems
Consider how this plays out with PII handling.
Take PII handling as an example.
Every organization has a policy. “Models must not be trained on unmasked PII. Chat-based assistants must not expose customer identifiers to other clients.” The language is clear. The intent is obvious.
Now ask where that policy becomes a constraint. Ask to see the system that prevents a data engineer from accidentally including unmasked customer records in a training dataset. Ask to see the filter that stops a chatbot from surfacing one customer’s information to another. Ask to see the access control that blocks non-compliant data from entering a training pipeline in the first place.
A mature organization should be able to show you these controls. They exist as code, configuration, and automated checks that run whether or not anyone remembers the policy. However, most organizations cannot show you this. They can produce the policy binder. They cannot produce the enforcement mechanism. The policy exists in a PDF. The training pipeline has no idea that PDF exists in the policy.
This is the core distinction. A serious enterprise AI governance framework is not defined by the quality of its policies but by the number of places where those policies have been translated into technical constraints that systems cannot bypass.
I.5. What Boards Actually Ask vs. What Governance Teams Deliver
Sit in a board meeting where AI comes up, and you will hear sharper questions than you heard two years ago:
- What decisions is AI making autonomously today?
- How do we know these systems are not discriminating?
- What happens when a model is wrong in a high-stakes context?
- Are we compliant with the EU AI Act and upcoming state-level AI laws?
- Who is accountable when AI fails?
Now watch what governance teams present in response. The mismatch is consistent.
Table 1: Board Questions and Response Types
| Board Question | Theater Response | Architecture Response |
| “What decisions is AI making autonomously?” | Inventory slides listing models and use cases | Decision catalog classified by autonomy tier (human-led, human-in-the-loop, straight-through) with named owners |
| “How do we know AI isn’t discriminating?” | High-level fairness statement, reference to bias testing done at launch | Documented fairness metrics per high-risk use case, periodic re-evaluation, drift alerts wired into monitoring |
| “What happens when a model is wrong?” | Description of escalation process, general human-in-the-loop statements | Concrete override pathways per decision type, logged overrides, and post-incident reviews tied to model updates |
| “Are we compliant with the EU AI Act?” | Policy mapping spreadsheets, vendor assurances, legal summaries | High-risk system register, Annex IV technical files, conformity assessment plan, traceable controls per requirement |
| “Who is accountable when AI fails?” | RACI charts with multiple roles accountable depending on context | Named decision owner per high-risk decision flow, transparent escalation chain, board-level metrics on decision quality |
The left column is descriptive and narrative, while the right column is structural and evidential.
Boards are shifting from accepting the first to expecting the second. The enterprises that cannot make that shift will eventually find themselves explaining why their governance program looked impressive in the boardroom but failed to prevent the incident now under investigation.
I.6. The Observability Void
There is one more question worth asking, and it is the most revealing: can you actually see what your AI systems are doing?
Most organizations can answer part of this. They can show you infrastructure metrics like CPU, memory, latency, and error rates. They can show you model-level metrics, such as aggregate accuracy and precision, on test datasets.
Ask them to show you decision-level visibility, and the picture changes:
- Which AI system influenced which specific decision?
- What data, prompt, and configuration were used at the moment of decision?
- Did the required human oversight actually happen?
- Did any decision violate policy even though the model output looked plausible?
These questions rarely have answers. The logs were designed for debugging, not decision reconstruction. The systems were instrumented for performance, not governance. Engineering and operations teams can troubleshoot an outage. Compliance teams cannot reconstruct why a customer was denied, flagged, or routed to a particular outcome.
Without decision-level visibility, governance becomes reactive. Problems surface through customer complaints, whistleblowers, press coverage, or regulator inquiries. By then, the damage is done. Incident investigation becomes an exercise in piecing together fragments from systems that were never designed to tell a coherent story.
This is the observability void. You cannot govern what you cannot see. You cannot claim compliance if you cannot reconstruct how decisions were made. And you cannot build meaningful oversight without knowing where AI is shaping outcomes in ways no one is watching.
II. The Supply-Side Problem: Implementor Ignorance and Enterprise Liability
Ask an enterprise governance team about their AI risk, and they will walk you through their model inventory. Data science projects. ML pipelines. Internal applications with embedded intelligence.
Now ask a different question. What about the AI running inside your CRM? Your claims processing platform? Your customer support tools? Your HR software? Who built those models? How were they evaluated? What data did they train on
The room gets quiet. Most governance programs were built for a world in which enterprises built their own models. That world is already obsolete. In today’s enterprises, a growing share of AI is embedded in SaaS platforms, third-party tools, and startup products that sit directly within critical business workflows.
The uncomfortable truth is simple: you are already running more AI you do not control than AI you do. If your governance program covers only what your data science team builds, it misses the majority of your actual risk surface.
II.1. The Governance Gap Nobody Discusses
Ask executives whether vendor AI is a concern, and they will say yes. Now ask to see how their governance framework treats vendors as AI actors.
You will find three patterns repeated across almost every organization:
Vendor risk questionnaires with dozens of security questions and one or two AI lines added as an afterthought. Contract clauses that push responsibility onto vendors but require no evidence that controls actually exist. Internal inventories that list “sales platform with AI features” without identifying the specific decisions that AI is making on the enterprise’s behalf.
Survey data confirms this disconnect. A large majority of C-suite leaders describe AI governance as strategic and critical. A single-digit percentage has concrete, enforced guidelines for acquiring and integrating AI-enabled tools.
Follow the money, and the gap becomes obvious. Governance investment flows to internal models. Third-party AI quietly shapes credit decisions, claims handling, underwriting, hiring, and customer support with far less scrutiny. The models your data science team builds get reviewed. The models your vendors embed in your workflows do not.
II.2. The Implementor Ignorance Tax

The supply-side problem has a second dimension, and it is more uncomfortable to discuss. A significant fraction of AI products on the market today are built by teams that do not fully understand model risk, security, or the regulatory context of the industries they sell into.
When you buy from that ecosystem, you inherit their ignorance as part of your risk profile.
Start with the skills gap. Breach reports consistently show that organizations with AI tools in production lack the in-house expertise to evaluate what those tools actually do. Security reviews focus on infrastructure: cloud providers, encryption, and access management. They skip model-level attack surfaces entirely. Prompt injection. Data poisoning. Insecure tool integrations. These risks do not appear on standard security checklists, so they do not get assessed.
Shift focus to code quality. AI-generated code is now integrated into many products on the market. Ask how much of that code has been reviewed for security, and you’ll find worrying numbers. Studies show that a large portion of AI-generated code comes with vulnerabilities right out of the box. Startups often ship quickly with AI-written integration logic that has never been exposed to a threat model.
Now consider regulatory alignment. Tools designed for banking, insurance, and healthcare are often developed by teams with little to no familiarity with OCC model risk guidance, NAIC bulletins, or FDA device regulations. The product functions correctly. It passes a demo. It meets a proof of concept. But it is fundamentally misaligned with the regulatory expectations of the industry it serves. The vendor isn’t aware of this. The enterprise doesn’t uncover it until an examiner asks questions nobody anticipated.
Think of this as an ignorance tax. Each time you choose AI from a vendor that hasn’t aligned with your regulatory needs, your governance program pays the price later through control issues, audit findings, remediation, or enforcement actions. The bill always comes due.
Table 2: The Implementor Ignorance Tax
| Ignorance Domain | Typical Startup Behavior | What the Enterprise Inherits |
| Model Risk Management | No formal MRM, limited documentation, no independent validation | No clear evidence for regulators or internal risk review |
| Security of AI Components | Focus on application security, ignore prompt injection and tool abuse | Must retrofit AI-specific controls and monitoring |
| Regulatory Alignment | “We are just a tool, not a regulated entity.” | Regulated entity bears full liability for outcomes |
| Data Governance | Broad data rights, vague retention policies | Hidden data residency and retention exposure |
| Change Management | Continuous deployment with minimal change logs | Impossible to reconstruct which version made a given decision |
II.3. Vendor Risk: The Liability Inheritance Chain
Traditional third-party risk management already recognizes that a meaningful share of breaches originates in vendor ecosystems. Recent data puts the number at roughly 30% of significant breaches, double the rate a year ago.
With AI, this chain becomes both more opaque and more consequential.
Walk through a typical enterprise deployment, and you will find four layers. At the foundation sits a model provider: OpenAI, Anthropic, Google, or an open-source base model. They control the training data, the behavior of the base model, and many systemic risks. One level up sits the vendor or startup. They wrap the foundation model in workflows, prompts, and tools. They handle storage, logging, and security for their product. Another level up sits the systems integrator or internal team that connects the vendor product into enterprise systems, data sources, and identity infrastructure.
At the top of this chain sits the enterprise. You remain accountable to regulators, customers, and courts for the outcomes.
Ask where regulators start their investigations, and the answer is consistent. They do not call the foundation model provider first. They call you.
Now look at the contracts. Vendors reserve broad usage rights over customer data “to improve the service.” They provide minimal documentation of AI components, training data, or evaluation methods. They disclaim responsibility for regulatory compliance and position themselves as neutral tools.
The enterprise ends up holding a familiar package: AI-driven decisions affecting customers and patients, minimal visibility into how the models were built, and contractual language that places liability squarely on the regulated entity.
II.4. The Shadow AI Multiplier
Official vendor AI is only part of the problem. Underneath the tools your procurement team approved sits another layer: shadow AI.
Employees sign up for AI-enabled SaaS using their corporate email. Teams wire copilot features into unofficial workflows. Departments experiment with agents using production data in labs that never get formally registered.
Shadow IT was already a governance problem. Shadow AI is worse for three reasons.
First, it can directly generate or influence decisions, not just store data. Second, it often uses live production credentials and accesses regulated information. Third, it bypasses whatever minimal governance exists for official AI projects.
Ask your identity provider or CASB vendor for telemetry on AI tool usage, and you will see the scale of it. Growth rates are measured in thousands of percent year over year. Most of these tools have no entry in any AI inventory. No risk assessment. No documentation. When something goes wrong, tracing the root cause across unofficial deployments is nearly impossible.
Your actual AI risk surface comprises three components: internal models you built, vendor AI in official tools, and shadow AI outside any governance program. Most enterprises only clearly see the first category.
II.5. The VC Pressure Dynamic
If we ask why vendors arrive with weak governance, the answer is structural. Their incentives point in a different direction than yours.
Startups get evaluated on growth metrics, customer logos, and shipping velocity. Governance adds friction. Documentation takes time. Rigorous evaluation slows releases. Funding cycles and investor pressure reward features rather than robust model risk management.
Look at the capital flows. AI funding exceeded $100 billion in 2024, an 80% increase over the prior year. One-third of all global venture funding now goes to AI companies. Late-stage deal sizes jumped from an average of $48 million in 2023 to $327 million in 2024.
That capital creates pressure. When competitors ship fast, and investors expect growth, governance becomes something to address later. Later often means never, or after an incident forces the issue.
None of this makes vendors malicious. It makes them rational actors responding to their incentive environment. Unless you explicitly require governance and architectural transparency, you will get the minimum legally defensible standard. That standard is rarely what your regulators expect.
From the enterprise side, this creates a bind. Business units want to move quickly and adopt AI tools. Vendor selection focuses on features and price. Governance requirements get introduced late or not at all. The result is painful cleanup projects, blocked adoptions, or worse: incidents that could have been prevented.
II.6. What Enterprises Must Demand
If governance is architecture rather than paperwork, then vendors are components in that architecture. They cannot be treated as black boxes.
Start with the minimum requirements for any AI-enabled product that touches high-risk decisions. Before signing contracts, require clear answers to basic questions.
Minimum Vendor Requirements
Before signing a contract, require:
- Architectural transparency: A diagram showing AI components, data flows, and integration points
- Model documentation: Description of model types, update cadence, and evaluation methodology
- Data governance commitments: Clear terms on data use, retention, residency, and whether your data trains their models
- AI security posture: How they address prompt injection, tool misuse, data exfiltration, and other AI-specific threats
- Change management: Versioning strategy, change logs, and advance notice on impactful updates
- Regulatory alignment: How their architecture maps to EU AI Act, sector guidance, and applicable state laws
- Incident and audit support: Commitment to support investigations and regulatory examinations with detailed logs
If a vendor cannot answer these questions clearly, that tells you something important about their governance maturity.
Technical Integration Requirements
On your side, assume vendor AI is untrusted by default:
- Gateway-based access: Route all vendor AI calls through an enterprise gateway that can log, filter, and constrain usage
- Scoped identity and permissions: Give vendor integrations least-privilege service accounts, never shared or human credentials
- Data minimization: Restrict inputs to what is necessary, with masking where possible
- Independent observability: Maintain your own logs of prompts, responses, and calls rather than relying solely on vendor logs
The enterprises that avoid inherited governance debt will be those that demand evidence of governance before integration. Those who assume vendors have their governance figured out will discover otherwise when regulators come calling.
III. The Regulatory Reality: EU AI Act Requirements
The European Union’s Artificial Intelligence Act entered into force on August 1, 2024. It is the world’s first comprehensive legal framework for AI, establishing binding requirements based on what AI systems do and who they affect, not just how data flows through them.
The Act applies to any organization that places AI systems on the EU market or puts them into service within the EU, regardless of the organization’s headquarters. It also applies to providers and deployers located outside the EU if their AI system’s output is used within the EU. For global enterprises, this means the Act’s requirements effectively become baseline even for systems developed elsewhere.
The Act is often compared to the GDPR, but the comparison goes only so far. GDPR regulates how organizations collect, store, and process personal data. The EU AI Act regulates how AI systems behave, regardless of whether personal data is involved. It treats AI as a product category with technical obligations, similar to how the EU regulates medical devices or machinery.
What makes this significant is the regulatory model. The Act classifies AI systems by risk level based on purpose and impact, then attaches specific technical requirements to each tier. High-risk systems require documented evidence of governance: how the system was designed, how risks were assessed, how human oversight works, and how performance is monitored over time. Policy statements and principles are not sufficient. Regulators expect architectural proof that controls exist and function.
The practical implications for enterprises are direct. Systems must be classified by risk tier, not by internal ownership. Technical documentation must go beyond policies to demonstrate traceable governance. And non-compliance carries real consequences: financial penalties up to €35 million or 7% of global turnover, mandatory corrective actions, and in severe cases, forced withdrawal from the EU market.
III.1. Timeline: What Has Already Started
The Act has four implementation deadlines. The first has already passed. The second arrives in months. Organizations planning for 2026 are late.
The first deadline passed on February 2, 2025, when rules on prohibited AI practices took effect. Systems that manipulate behavior through subliminal techniques, exploit vulnerabilities of specific groups, or enable social scoring by public authorities are now banned. Organizations still operating systems in these categories are already non-compliant.
The second deadline arrives on August 2, 2025, when General Purpose AI model rules take effect. Foundation model providers must maintain technical documentation, supply information to downstream deployers, comply with copyright requirements, and publish summaries of training content. Models designated as having systemic risk face additional obligations, including adversarial testing and incident reporting.
The third deadline, August 2, 2026, receives the most attention. This is when most high-risk system requirements become enforceable. By this point, two earlier milestones will have passed. Organizations that treated 2026 as their starting line will find themselves addressing obligations that took effect months or years earlier.
The fourth deadline, August 2, 2027, applies to high-risk systems already covered by existing EU product safety legislation. Medical devices, machinery, and other Annex I products with AI components must comply by this date.
III.2. High-Risk Classification
The Act divides AI into four categories: prohibited, high-risk, limited-risk, and minimal-risk. For most enterprises operating in banking, insurance, and healthcare, the critical category is high-risk.
High-risk systems are defined less by algorithm and more by where they sit in consequential processes. Annex III specifies the domains that trigger high-risk classification. Access to essential private services covers credit scoring, lending decisions, insurance pricing, and customer acceptance or denial. Employment and worker management covers hiring, promotion, performance evaluation, workforce allocation, and termination decisions. Healthcare and essential services cover triage, diagnostic support, treatment recommendations, and resource allocation in care pathways.
A system becomes high-risk when it materially influences decisions in these areas. The word “materially” carries weight. A model that scores loan applications is high-risk, whether or not a human technically approves the final decision. A hiring tool that ranks candidates is high-risk even if labeled “just a recommendation,” particularly if that recommendation is followed most of the time.
Two classification mistakes appear repeatedly in enterprise inventories. The first is labeling something as “internal tooling” when it directly affects individuals. A risk-scoring model used by underwriters is categorized as internal support because no customers see the interface. The Act does not care about interface visibility. It cares about the impact on natural persons. The second mistake is treating “advisory” systems as low-risk. Systems positioned as assistive can still qualify as high-risk if operators treat outputs as authoritative, or if workflows make meaningful override impractical. A recommendation followed 98% of the time is, in effect, a decision.
Classification depends on both intended purpose and actual use. Governance frameworks that examine only what systems are supposed to do, without studying how they are actually used, will misclassify.
III.3. Provider vs. Deployer: Where Do You Sit?
The Act creates two distinct roles with different obligations. Providers are organizations that develop AI systems or place them on the market under their own name or trademark. They bear the heaviest obligations: technical documentation, conformity assessment, quality management systems, post-market monitoring, and incident reporting. Deployers are organizations that use AI systems under their own authority for professional purposes. This is where most enterprises sit. They did not build the AI, but they are using it in their operations.
The distinction matters because deployer obligations are lighter than provider obligations, but they are not trivial.
Deployer obligations under Article 26 include:
- Using systems in accordance with provider instructions
- Assigning human oversight to trained, competent personnel
- Verifying that input data is relevant and sufficiently representative
- Monitoring for risks during operation
- Reporting incidents to providers
- Keeping logs for at least six months or as specified by the provider
- Informing workers when AI is used in employment decisions
- Conducting a fundamental rights impact assessment before deploying certain high-risk systems
That last requirement deserves attention. Before deploying high-risk AI in areas such as employment, credit, or essential services, deployers must assess its impacts on fundamental rights. This assessment must document the processes in which the system will be used, the frequency of use, the categories of persons affected, the specific risks of harm, the human oversight measures, and the steps to take if risks materialize.
One critical point: an enterprise can shift from deployer to provider. If you substantially modify a system or place a system on the market under your own name, you assume provider obligations. White-labeling a vendor’s AI product can make you the provider in regulators’ eyes.
III.4. Technical Documentation Requirements (Annex IV)
Once a system is classified as high-risk, the Act expects a technical file demonstrating how the system was designed, built, tested, and governed. Many organizations interpret this as producing more documents. That framing misses the point. The Act seeks architectural evidence, not paperwork volume. The question is whether documentation demonstrates traceable governance from design through deployment.
Annex IV requires six categories of evidence:
- System description and intended purpose: What the system does, where it operates, what decisions it supports, the population it affects, and the operational context.
- Design and development process: Architecture diagrams, design choices, model families, dependencies on upstream systems and vendors.
- Data governance and lineage: Sources of training and evaluation data, data quality and representativeness, known limitations, preprocessing methods, and refresh cadence.
- Risk management and controls: Identified risks across fairness, robustness, security, and misuse. Technical and procedural mitigations. Residual risk and ongoing monitoring approach.
- Human oversight design: Where humans enter the decision flow, what authority they have to override or stop the system, and how meaningful control is maintained operationally.
- Performance, robustness, and accuracy: Quantitative metrics under expected conditions, stress, and edge case testing, monitoring strategy to detect drift and degradation.
What most organizations have today is a model card for some models, ad-hoc evaluation reports scattered across teams, and architectural diagrams buried in old slide decks. What regulators expect is a coherent technical file for each high-risk system, in which design, data, risk management, oversight, and monitoring all trace back to a defined purpose. The gap is traceability, not volume.
III.5. General Purpose AI: Your Foundation Model Exposure
Most enterprises do not build foundation models. They use them. OpenAI, Anthropic, Google, Meta, and others provide the base models that power enterprise AI applications. The Act creates a separate category for these General Purpose AI models with obligations that take effect in August 2025.
GPAI model providers must:
- Maintain technical documentation on training and testing
- Provide information to downstream deployers
- Establish policies for copyright compliance
- Publish summaries of training content
GPAI models with systemic risk face additional requirements:
Models trained with compute above 10^25 FLOPs are presumed to have systemic risk. These models require adversarial testing (red-teaming), incident tracking and reporting, and cybersecurity protections.
For enterprises, this creates a dependency chain. Your high-risk applications may run on GPAI models. You need assurance that your model provider is meeting their obligations. You need the documentation they are required to supply. If your provider cannot demonstrate GPAI compliance, your own compliance position is weakened. When evaluating GPAI providers, require evidence of technical documentation for the model, their copyright compliance approach, content summary publication, and, for systemic risk models, adversarial testing results, and incident tracking procedures.
III.6. Conformity Assessment
High-risk systems must undergo conformity assessment before being placed on the EU market or put into service. Most Annex III high-risk systems can use the internal control procedures in Annex VI, which means self-assessment against the requirements, provided you have a complete technical file and can demonstrate compliance. The exception is remote biometric identification systems and certain critical infrastructure AI, which require third-party assessment by a Notified Body under Annex VII. External reviewers examine your technical file, risk management approach, and controls.
Notified Body capacity is limited. The EU is still building its certification infrastructure, and organizations that require third-party assessment face queues and should plan accordingly.
Three things are consistently underestimated. The first is the time required to prepare a high-quality technical file for even one complex system. Expect months, not weeks. The second is the iteration cycles when assessors push back on incomplete evidence. Internal documentation that seems adequate often fails external review. The third is vendor dependency. If your high-risk system uses third-party AI components, you need documentation from those vendors. Their delays become your delays. Conformity assessment cannot be bolted on in early 2026. It depends on architecture, documentation, and risk management decisions made now.
III.7. Transparency Obligations for Limited-Risk AI
Not all AI is high-risk, but lower-risk systems still carry transparency obligations that many enterprises overlook.
- AI systems interacting with humans must disclose that users are interacting with AI. Customer service chatbots, virtual assistants, and conversational interfaces need clear disclosure.
- Emotion recognition and biometric categorization systems must inform individuals that they are being subjected to such systems.
- Deep fakes and synthetic content must be labeled as artificially generated or manipulated.
These requirements apply regardless of risk classification. A customer-facing chatbot may not qualify as high-risk, but it still requires transparency about its nature.
III.8. Penalty Structure
The Act establishes three penalty tiers tied to different violations.
- Prohibited practices: Up to €35 million or 7% of global annual turnover, whichever is higher. This covers banned uses of AI, such as manipulative systems and social scoring.
- High-risk obligation failures: Up to €15 million or 3% of global annual turnover. This covers failures in documentation, risk management, human oversight, or logging requirements.
- Supplying incorrect information: Up to €7.5 million or 1% of global annual turnover. These covers provide false or misleading information to authorities or fail to cooperate with investigations.
Beyond financial penalties, authorities can suspend or restrict market access, mandate corrective actions, and, in severe cases, force the withdrawal of non-compliant systems from the market.
For critical systems in banking, healthcare, or insurance, forced withdrawal is more damaging than any fine. You lose operating capability. You rebuild under regulatory supervision. You simultaneously absorb reputational and legal consequences.
III.9. The Substantial Modification Trap
AI systems are not static. During the lifecycle of this application, Models get retrained. Prompts and configurations get adjusted. New features and data sources get added.
The Act accounts for this through the concept of substantial modification. Certain changes trigger reassessment obligations:
- Changing the intended purpose of the system
- Expanding to new populations with different risk profiles
- Changing core model architecture in ways that materially affect behavior
- Adding data sources that alter bias profiles or robustness
When a modification is substantial, the system is treated as new for compliance purposes. You may need to repeat parts of the conformity assessment. Your regulatory role might shift from deployer to provider.
For organizations that continuously update models, this creates a compliance treadmill. Frequent improvement requires frequent demonstration that changes remain within the original risk posture.
Without disciplined change management, you cannot distinguish minor updates from substantial modifications. Without versioning and evaluation pipelines, you cannot compare behavior across versions. Without clear decision rights, changes occur ad hoc, creating audit exposure.
This is where governance becomes architectural. You need infrastructure to track what changed, when it changed, who approved it, and whether the change altered the risk profile. Without that infrastructure, you cannot maintain compliance across a system’s lifecycle.
IV. Industry-Specific Regulatory Landscape
The EU AI Act creates a broad framework applicable across all sectors. However, in regulated industries, it does not replace existing oversight but adds to the rules that have long governed issues such as model risk, consumer harm, discrimination, and safety. Regulators will continue to evaluate AI using their established perspectives.
This means that enterprises in banking, healthcare, and insurance will not need to create new governance for AI. Instead, they will build on their current supervisory expectations to cover AI-enabled decisions. The key issue is not whether existing frameworks are applicable, but whether your AI architecture can generate the evidence that these frameworks have always demanded.
IV.1. Banking: Model Risk Management Extended
Banks already follow mature supervisory standards for managing model risk. The key guidance, SR 11-7 from the Federal Reserve and OCC Bulletin 2011-12, is not specific to AI. This is exactly why it’s important. It applies to any “model” involved in decision-making, broadly defined as a quantitative method that takes inputs and produces outputs to support decision-making. Whether the model is linear regression, gradient boosting, or an LLM-based scoring pipeline, the supervisory expectation remains the same: the bank must show effective model risk management.
What changes with AI are not about the existence of oversight, but the nature of the evidence you need to provide.
- Model boundaries are fuzzier (prompts, retrieval, tools, agents).
- Versioning is more frequent (prompt edits, policy updates, and changes to the retrieval corpus).
- Failure modes include discrimination, instability, and security manipulation—often without obvious “errors.”
The practical implications extend across five areas.
- Treat AI decisioning as a “model” under MRM.
- Include it in the model inventory, validation cadence, and governance forums.
- Separate “decision design” from “model performance.”
- Governance needs to cover: decision thresholds, override logic, escalation, and adverse action traceability, not only accuracy.
- Fair lending posture becomes architectural.
- You need evidence that discrimination controls are enforced at runtime (and re-validated after changes), not asserted in policy.
- Third-party AI becomes first-class in TPRM.
- Vendor AI must provide architectural evidence: what decisions it influences, how it is validated, how it changes, and what audit logs exist.
- Change management is no longer optional.
- Prompt/configuration changes are “model changes” in impact terms and should be governed as such.
The Consumer Financial Protection Bureau has signaled increased focus on algorithmic discrimination and adverse action requirements. When AI influences credit decisions, lenders must still provide specific reasons for adverse actions. “The model decided” is not a compliant explanation. The architecture must support reason code generation that traces back to factors the applicant can understand and potentially address.
IV.2. Healthcare: Safety as the Governing Principle
Healthcare AI governance is more focused on fairness and transparency than on safety and effectiveness alone. In the US, the FDA regulates AI-enabled medical devices under its existing authority over software as a medical device, and the agency has been actively developing guidance specific to AI and machine learning.
As of late 2024, the FDA had authorized more than 1,000 AI and ML-enabled medical devices for marketing in the United States, spanning radiology, cardiology, ophthalmology, and numerous other clinical domains. The agency maintains a public database of these authorizations, and the pace of submissions continues to accelerate. This is not a future regulatory concern. It is a current operating reality for health systems deploying AI in clinical workflows.
Two concepts matter operationally for healthcare AI governance.
- Total Product Lifecycle thinking
Healthcare regulators increasingly expect controls that span the lifecycle: design → validation → deployment → monitoring → updates. This is not a one-time “launch review”; it’s continuous governance, especially for systems that learn or change over time. - PCCP (Predetermined Change Control Plan)
FDA guidance on PCCPs exists because AI changes are inevitable. The core idea: you pre-specify what will change, how you will evaluate those changes, and how you maintain safety and effectiveness while updating.
What are these forces inside the enterprise:
- A documented update pathway (what changes are allowed, what triggers re-validation).
- Monitoring that is tied to clinical risk, not just ML drift metrics.
- Clear labeling/communication: what the system is intended to do, what it is not intended to do, and what limitations exist. (This becomes critical for “meaningful human oversight” in clinical settings.)
That labeling requirement is crucial for meaningful human oversight in clinical environments. Clinicians need to understand system limitations to exercise proper judgment. The deployment of the Epic Sepsis Model, which we will analyze later, shows what occurs when a model is implemented without proper decision-rights architecture and clinical oversight. The issue was not related to model accuracy but to governance.
IV.3. Insurance: The NAIC Framework Takes Hold
Insurance regulators have moved faster than many enterprises realize. The National Association of Insurance Commissioners published a Model Bulletin on the use of artificial intelligence by insurers, and states have been adopting it steadily. As of March 2025, 24 states had adopted the NAIC Model Bulletin or issued substantially similar guidance. Additional state-level requirements continue to accumulate.
The Model Bulletin establishes expectations that insurers should assume will become baseline. Insurers must maintain the following.
- Documented governance program (scope, roles, approvals).
- Controls for data, bias, and explainability.
- Vendor oversight as part of the AI program (not separate procurement paperwork).
- Audit-ready artifacts: decision logs, change logs, and accountability mapping.
Insurers cannot treat AI as an experimental analytics layer sitting outside normal governance. They must operate AI as a regulated decision system subject to the same expectations that apply to underwriting, pricing, and claims decisions made through traditional means. When an AI system influences whether to accept a customer, how to price a policy, or whether to pay a claim, that system must produce the evidence regulators expect for any consequential decision.
Colorado has gone further than the NAIC baseline. Senate Bill 21-169 requires insurers to test for unfair discrimination in AI systems used for insurance practices. The law creates specific documentation and testing requirements that take effect in 2025 and 2026, with ongoing compliance obligations thereafter. Insurers operating in Colorado face requirements that exceed the NAIC Model Bulletin, and other states may follow Colorado’s more prescriptive approach.
IV.4. The Common Pattern
The pattern is consistent across banking, healthcare, and insurance: regulators don’t reward aspirational statements but value the ability to demonstrate governance in real decisions. A policy document on responsible AI isn’t enough as evidence. True evidence shows which decision was made, the influencing factors, the system version that made it, the approver of that version, and how the system is monitored for issues.
Existing regulatory frameworks already mandate this evidence for consequential decisions. AI doesn’t introduce new obligations but rather presents new challenges in fulfilling longstanding ones. The key question for regulated companies is whether their AI systems can generate the audit trail that regulators have traditionally required.
V. The US State AI Regulatory Patchwork
With no comprehensive federal AI legislation in place, regulatory control in the United States is increasingly shifting to the states. This leads to a complex compliance landscape, where requirements arise from two sources: new AI-specific laws and the reinterpretation of existing civil rights, consumer protection, and privacy laws for automated decision-making systems.
For companies operating nationwide, this creates architectural challenges. They cannot develop governance for a single jurisdiction and assume it applies elsewhere. Waiting for federal guidance may be futile, especially if state enforcement starts first. Furthermore, treating state differences as legal issues to be resolved by separate policies is inadequate. Instead, systems need to incorporate capabilities that can handle diverse legal requirements seamlessly without redesigning governance for each state.
V.1. Colorado AI Act: The Template
Colorado’s AI Act, Senate Bill 24-205, serves as the clearest example of a comprehensive state law focused on algorithmic discrimination and reasonable care responsibilities. The law applies to both developers of AI systems and users who make consequential decisions with them. The original effective date of February 1, 2026, has been pushed back to June 30, 2026, but the compliance timeline remains tight for organizations that haven’t begun preparing. —
The law targets high-risk AI systems, defined as systems that make or play a significant role in making important decisions in areas such as employment, education, financial services, healthcare, housing, insurance, and legal services. For organizations deploying these systems, the law requires a risk management policy and program, completion of impact assessments for high-risk systems, disclosure to consumers when AI is used in important decisions, and documentation of how the organization exercises reasonable care to prevent algorithmic discrimination.
Architecturally, the key aspect is the compliance logic. The law establishes a rebuttable presumption framework under which deployers who meet certain criteria—such as conducting impact assessments, adhering to risk management protocols, and effectively addressing known risks—are presumed to have acted with reasonable care. This shifts the burden of proof to the plaintiffs to disprove this presumption. Deployers unable to demonstrate these practices lose the presumption and must then contend with a tougher defense.
For enterprises operating across the country, Colorado provides a template that other states can follow or modify. The mix of impact assessments, anti-discrimination measures, documentation standards, and consumer disclosures creates a baseline of governance. Progressive organizations should consider this as a minimum standard, even in states without similar laws. Aligning with Colorado’s standards prepares you to accommodate future state regulations without needing a major redesign.
V.2. California: Existing Law, New Application
California is adopting an alternative strategy. Instead of developing separate AI laws, the state is enhancing how current anti-discrimination laws cover automated decision-making systems in employment.
The California Civil Rights Council has finalized regulations effective October 1, 2025, that clarify how the California Fair Employment and Housing Act applies to the use of automated decision systems in employment. These regulations do not establish a new legal framework but specify existing requirements for hiring, promotion, termination, compensation, and performance evaluation when automated systems are used.
If an automated decision system influences employment decisions in California, it is subject to existing discrimination laws. Employers must prevent these systems from causing disparate impact on protected groups. Relying solely on vendor claims that the system is fair will not convince regulators or withstand legal challenges. Instead, employers need solid evidence such as testing data, documentation of evaluation and monitoring processes, and clear governance over how the outputs are used in decisions.
This is precisely where the supply-side issue turns into liability. Employers cannot shift accountability to vendor marketing claims. When a vendor’s AI system results in discriminatory outcomes, the employer, not the vendor, faces enforcement action. California’s approach clearly states what was previously implicit: employers are accountable for the tools they select, and accountability requires proof of due diligence.
V.3. Illinois: Disclosure and Documentation
Illinois passed House Bill 3773, which amends the Illinois Human Rights Act to regulate the use of AI in employment decisions. The law becomes effective on January 1, 2026.
The Illinois approach is more limited than Colorado’s broad framework, but indicates the general direction. Employers employing AI for recruitment, hiring, promotion, employment renewal, training selection, discharge, discipline, tenure, or employment terms must notify employees and applicants. The law also bans using AI in ways that could lead to discrimination against protected classes.
The notice requirement changes employers’ approach to AI deployment. Systems previously viewed as internal tools must now be disclosed. This adds documentation responsibilities even for employers who believe their systems are free of discrimination. Employers must identify where AI is used in employment processes, inform affected individuals about its use, and show that these systems do not cause discriminatory results.
V.4. New York City: Local Enforcement Begins
New York City’s Local Law 144, enacted in July 2023, serves as an early example of enforcement. It mandates that employers and employment agencies that use automated decision tools must conduct annual bias audits by independent auditors and notify candidates and employees accordingly.
The law pertains to tools that significantly aid or substitute for discretionary decisions in hiring or promotion. Employers subject to this law are required to publish the results of their bias audit on their websites, inform candidates about the use of an automated tool, specify the qualifications and traits the tool assesses, and explain how candidates can request an alternative selection process or accommodations.
Enforcement has been limited during the law’s first year, but the New York City Department of Consumer and Worker Protection has started investigating complaints and providing guidance. For employers nationwide, Local Law 144 is a current compliance requirement, not one set for 2025 or 2026. Organizations that use automated hiring tools for New York City jobs should already have bias-audit procedures in place.
V.5. The Pattern Across Jurisdictions
Across states and localities, five themes appear consistently regardless of the specific legal mechanism.
- Disclosure and transparency: Individuals must be informed when automated systems materially influence decisions affecting them, whether the legal basis is new AI legislation, existing consumer protection authority, or civil rights enforcement.
- Anti-discrimination as the dominant lens: Employment and consumer decisions are the primary enforcement targets because they connect to established legal frameworks. Regulators and plaintiffs’ attorneys are applying familiar discrimination theories to new technology. The tools are new; the legal principles are not.
- Impact assessment as compliance standard: Organizations must demonstrate reasonable care by documenting foreseeable risks, implementing controls, and maintaining evidence of ongoing governance. Aspirational commitments are not sufficient. Organizations must show their work.
- Rising vendor accountability: Courts and regulators are increasingly skeptical of arguments that shift responsibility to technology providers. The organization that deploys a system bears accountability for its outputs. Procurement due diligence is a precondition for ongoing governance, not a defense.
- Evidence defeats intent: Organizations face liability without malicious purpose if they cannot produce artifacts demonstrating how systems were evaluated, monitored, and governed. Absence of evidence of harm is not evidence of reasonable care. You must show what you did, not just assert what you intended.
V.6. Architecture Implications
A multi-state enterprise cannot manage AI solely through policy documents and annual committee reviews. The differences between jurisdictions, the rapid development of new requirements, and regulators’ expectations for evidence demand system-level capabilities.
You require a maintained inventory of AI systems classified by use case and risk level. Additionally, you need decision classification to determine which systems are subject to specific jurisdictional requirements. Oversight mapping is necessary to document approval authorities and decision-making flow within the organization. Change control processes must track modifications and initiate appropriate reviews. Finally, audit-ready logging should provide regulators with evidence in any jurisdiction without the need for custom extraction.
These capabilities are not limited by jurisdiction. They must be created once and then configured to handle legal differences. Rebuilding governance for each new state law is too costly. Instead, investing in developing reusable capabilities that adapt to variation is more sustainable and pays off as the number of requirements grows.
VI. Emerging Threats: Agentic AI Security
Agentic AI fundamentally transforms the security landscape. Unlike traditional AI, which only produces text, agentic systems take action. They can read files, use tools, query databases, execute code, send messages, and coordinate multiple steps across workflows. When an agent is compromised, the consequences are no longer just incorrect answers. Instead, it can lead to unauthorized access, data theft, record manipulation, privilege escalation, or a chain of actions affecting interconnected systems.
This is why AI governance should go beyond fairness, bias testing, and documentation. For agentic systems, governance must involve a security architecture designed with the understanding that the model can be deceived and that it includes measures to contain potential damage. The most crucial controls are not just policies against misconduct but architectural restrictions that limit the harm a compromised agent can cause.
VI.1. Why Agents Create New Attack Surfaces
Traditional applications are deterministic, with application logic (code) dictating system behavior and data processed based on this logic. This approach assumes a stable boundary between instructions and data, where code instructs the system what to do, and data is handled accordingly. These elements are kept separate by design.
Large language models do not have that boundary. Instructions and data arrive in the same channel, processed by the exact mechanism. This is why prompt injection remains structurally difficult to eliminate. You cannot simply filter malicious instructions from legitimate data when the model treats all text as potential instructions.
Agentic systems amplify this problem by adding capabilities. A chatbot that produces wrong answers is embarrassing. An agent that produces wrong answers while holding credentials to production databases, email systems, and code repositories is dangerous. The attack surface expands with every tool the agent can call, every system it can access, and every action it can take without human approval.
VI.2. The Agent Threat Taxonomy

OWASP’s Agentic Security Initiative has formalized threat categories for agentic applications. A practical enterprise threat taxonomy should address five categories:
- Goal and instruction hijacking: Hostile instructions embedded in content the agent consumes during normal operation. Attackers place malicious directives in documents, support tickets, web pages, or emails that the agent reads. The agent follows these injected instructions because it cannot reliably distinguish them from legitimate requests.
- Tool misuse and output injection: The agent is coaxed into using legitimate tools in unexpected ways. It has permission to query systems, export data, or modify records. An attacker exploits this by tricking it into misusing these capabilities. The tools function correctly; the problem lies in the agent’s decision-making about when to use them.
- Identity and delegation abuse: Agents operating under overprivileged service accounts or flawed delegation models. An agent granted broad permissions for convenience becomes a high-value target. Compromising the agent grants the attacker everything the agent could potentially do.
- Memory poisoning: Attackers contaminate persistent memory or retrieval stores with hostile directives disguised as historical context or false facts. The poisoning occurs once but influences agent behavior indefinitely until detected and remediated.
- Inter-agent poisoning: Communication channels between agents become injection surfaces. A compromised agent can manipulate other agents through the same techniques that work against human-facing interfaces.
VI.3. Real-World Attack Patterns
These are not merely hypothetical risks. Production systems have already been compromised through these mechanisms.
In November 2025, security researchers demonstrated how ServiceNow’s agent-to-agent discovery process could be exploited via second-order prompt injection. This attack enabled unauthorized activities such as data exfiltration and record modifications. The vulnerability stemmed from default settings rather than a coding flaw. The system functioned as intended; however, the design did not account for malicious inputs passing through inter-agent communication channels.
CVE-2025-32711, listed in the NIST National Vulnerability Database, is an AI command-injection flaw in Microsoft 365 Copilot. Known as EchoLeak in security research, it allowed information disclosure without any user interaction. This was not just a proof-of-concept; it was a confirmed vulnerability in a widely used production system that affected millions of enterprise users. This highlights that prompt injection attacks can successfully target commercial products from major vendors.
In December 2025, security researchers published their findings on AI-assisted development tools under the name IDEsaster. They discovered widespread vulnerabilities in coding assistants, including risks of data exfiltration and, in some instances, remote code execution. The combined capabilities of agents, tool access, and file system permissions created new attack pathways not present in traditional development settings. These results reflect broader enterprise concerns about the security of AI code assistants, especially given issues like hallucinations, data leaks, and insecure code generation, which heighten risks in development workflows.
These incidents follow a common pattern. The model itself is not faulty, and the system functions as intended. However, the design assumed harmless inputs and trusted the model’s judgment about privilege boundaries. Under adversarial conditions, these assumptions break down.
VI.4. The Agentic Security Paradox
Enterprises deploy agents to compress the time from intent to action. A task that requires multiple steps across multiple systems and multiple approvals can be consolidated into a single request that the agent executes autonomously. That compression generates value. It also removes the safety valves that traditional security relies on.
Human review checkpoints are removed when agents operate autonomously. Explicit approval workflows are eliminated when agents are allowed to proceed without delay. Narrow tool permissions become irrelevant when agents require broader access to function effectively. Each mechanism that was originally designed to contain damage from compromised systems is weakened to enhance agent effectiveness.
This creates a paradox: as you give an agent greater autonomy to produce value, you must also invest more in managing boundaries to control the risks that autonomy entails. Elements like identity management, tool permissions, policy enforcement, logging, and rollback capabilities become increasingly crucial as agent autonomy grows, rather than less so.
Organizations that govern agents the same way they govern traditional AI, focusing only on model selection, training data quality, and bias testing, will miss the failure modes that manifest as security incidents rather than model errors.
VI.5. NIST Evaluations and Guidance
NIST explicitly identifies agent hijacking as a top risk category. The attackers exploit the agent’s difficulty distinguishing harmless data from malicious commands by hiding adversarial instructions within resources the agent typically processes. This includes documents, emails, web pages, and files, all of which can serve as attack vectors.
NIST evaluations now cover priority risks, including:
- Remote code execution through agent manipulation
- Database exfiltration via compromised agent queries
- Automated phishing, where agents send malicious communications on behalf of users
This is important for governance because it affects the practical meaning of controls. It’s not enough to test whether an agent is helpful and accurate; you must also verify whether the agent can be forced to use unsafe tools in real-world scenarios, with adversarial inputs passing through the channels the agent monitors in deployment.
VI.6. Security Architecture Requirements
Security policies tell agents what not to do. Architecture prevents them from doing it. For agentic AI, governance must specify both, because a compromised agent will not read your policies before exfiltrating your data.
The minimum requirements that hold up in regulated environments:
- Access control and least privilege: Agents operate with scoped identities granting only permissions required for designated functions. Sensitive tools require additional authentication or approval gates. The blast radius of a compromised agent is limited by the permissions it holds.
- Tool allowlists and parameter constraints: Tools are treated as privileged interfaces. Agents can only call explicitly permitted tools, with constraints on parameter values and action ranges. An agent authorized to query a database may be constrained to specific tables, row limits, or query patterns.
- Input validation and content hardening: Assume hostile content will reach the agent through normal channels. Architecture should minimize the extent to which untrusted content influences action selection through content filtering, instruction isolation, or separation between content processing and action execution.
- Memory governance: Maintain separation between durable memory and untrusted context. Detect potential memory poisoning and support rollback to known-good states. Long-term memory stores require the same integrity protections as other critical data.
- Observability and forensics-grade logging: Capture decision lineage: inputs received, tools called, parameters used, outputs produced, policies evaluated. This connects directly to audit trail requirements. You cannot demonstrate governance without logs that reconstruct what the agent did and why.
- Containment and contingency planning: Stop mechanisms halt the operation of agents when anomalies are detected. Throttles limit the rate of consequential actions. Rollback paths reverse tool actions when a compromise is identified. Incident playbooks specify response procedures.
For a comprehensive treatment of red teaming methodologies and security testing frameworks for agentic systems, including adversarial testing approaches mapped to ISO 42001, NIST AI RMF, and the EU AI Act, see “LLM Red Teaming 2025: A Practical Playbook for Securing Generative AI Systems.” Organizations deploying agents via integration protocols should also review “Model Context Protocol (MCP): The Integration Fabric for Enterprise AI Agents,” which addresses prompt-injection risks, tool security boundaries, and enterprise deployment architecture.
VI.7. The Governance Connection
Regulators increasingly expect evidence that organizations can control high-risk decisions. Agentic systems increase the likelihood that a control failure will escalate into a security event with immediate, substantial consequences.
A bias in a scoring model may harm individuals over time in ways that are difficult to trace. A compromised agent can exfiltrate a database in minutes, send phishing emails to thousands of contacts in seconds, or modify records across systems before anyone notices. The failure modes in these cases are more rapid, more visible, and highly likely to trigger regulatory and legal consequences.
When an agent security incident triggers both a data breach notification and questions about AI oversight, the line between AI security and AI governance disappears. The controls are interconnected. The architecture must be as well.
VII. Governance as Infrastructure: The CTRS Framework
From the earlier sections, we observed that governance often fails because organizations view it as a policy addition rather than a system framework. Risks increase due to vendor AI that enterprises cannot control and shadow AI that remains unseen. As EU regulations layer on top of sector-specific rules and state laws, compliance becomes more complex. Agentic AI transforms governance lapses into security incidents with direct, immediate impacts.
The question is: what does governance architecture actually look like when it works?
CTRS, the Control Tower Reasoning System, treats governance as a decision control plane. It sits above models, vendors, and agents, providing the infrastructure required to answer the questions boards and regulators now ask. What decisions are being made? Under what authority? With what oversight? With what evidence? With what change control?
Governance programs produce documents, committees, and periodic reviews. CTRS is a governance architecture in which components and contracts enforce policy at runtime, when decisions are being made.
VII.1. Pillar I: Decision Velocity
Most governance programs assume a tradeoff: increasing governance often leads to slower delivery. Teams tend to resist governance because it introduces friction, causes delays in launches, and creates approval bottlenecks.
CTRS operates on a different premise. By encoding governance as infrastructure, it accelerates decision-making by minimizing uncertainty, rework, and approval hurdles. Teams can move more quickly because they follow established processes instead of renegotiating governance for each project.
Decision Velocity measures the duration from receiving a signal to interpreting it, making a decision, and taking action, all within certain constraints. It serves as the primary metric for assessing whether AI investments lead to tangible business results. Instead of focusing solely on model accuracy, organizations should aim to optimize the speed at which accurate predictions are converted into governed actions.
In most enterprises, governance delays progress because it comes too late. A model is created, a pilot begins, and then governance requests documentation, controls, testing, and approvals. This causes delivery to pause as teams retrofit architecture and rewrite workflows. As a result, governance often becomes the department responsible for delays.
CTRS increases Decision Velocity by prioritizing governance upfront and ensuring reusability. It defines decision classes to specify the types of decisions and their associated risk levels. Oversight patterns are standardized across different tiers, clearly indicating which decisions can be automated, which need human review, and which require escalation. Logging and audit capture are implemented once via gateways, avoiding multiple re-implementations by different teams. Policy-as-code is uniformly applied and evaluated at the moment of decision-making instead of during quarterly reviews.
The practical outcome is that teams can work more quickly because governance questions are already settled. They aren’t debating which controls to implement or what documentation to provide. Instead, they are deploying onto infrastructure that manages governance automatically.
VII.2. Pillar II: Trust Layer and Version Drift Prevention
Enterprise AI failures in production are more frequently caused by system drift than by poor model quality.
Drift is not only about model weights. In modern AI systems, it also stems from prompt modifications that influence system behavior, changes in retrieval corpora as documents are added or re-indexed, variations in tool availability and parameters as integrations develop, vendor model updates that occur unexpectedly, and policy shifts that alter permissible content or actions.
This is version drift. Yesterday’s system is not today’s system, even when the model, prompt, and code remain unchanged. The risk is not inaccuracy. It is confident about the wrong version. When regulators or plaintiffs examine the logs, they find a system that retrieved valid information that happened to be superseded, and an organization with no mechanism to prevent it.
CTRS addresses this through a Trust Layer built on dual-index architecture. The content index tracks the available knowledge: documents, embeddings, and external data sources. The governance index tracks what constraints are in force: policies, decision rights, allowed tools, risk posture, model versions, and prompt versions.
At decision time, CTRS enforces both. It validates what the system knows against the content index and what the system is allowed to do against the governance index. A query that would retrieve a superseded policy document is blocked before it reaches the model. An action that would violate current constraints is stopped before it executes.
This is how you prevent compliance drift, where a system gradually evolves away from what was originally approved, and no one notices until an audit or incident reveals the gap.
The Air Canada chatbot case illustrates what happens without this protection. Customers received incorrect policy information, and the company was held responsible. The lesson is not that chatbots are risky. The lesson is that without governance-state enforcement, systems will confidently produce outcomes that contradict official policy even when the underlying model is functioning normally.
VII.3. Pillar III: Agent Governance via Model Context Protocol
Agentic systems add a governance requirement that did not exist for traditional AI. You are no longer governing only outputs. You are governing actions.
Model Context Protocol has emerged as a practical standard for connecting models to tools, data sources, and services. In enterprise environments, MCP becomes the obvious integration fabric for agentic systems. It also becomes the obvious governance choke point.
CTRS treats MCP orchestration as something that must be governed through explicit components:
- Capability registry: A catalog of what tools exist, what they do, and what risk tier they occupy. You cannot govern tools you have not inventoried.
- Policy engine: Rules specifying what tools can be used under what conditions, with what data constraints, enforced as policy-as-code at runtime.
- Identity and delegation: Agents act under delegated identity with least privilege, not blanket service credentials. The on-behalf-of model ensures agents operate within the permissions of the user they represent.
- Decision lineage capture: Every tool call, input, and output is recorded as reconstructable evidence. You can answer what the agent did, why, and what information it had.
- Rollback and containment controls: The ability to stop, throttle, or revert actions when anomalies occur. Kill switches and rate limits provide defense in depth.
This is the MCP Gateway Pattern. Agents do not call tools and data sources directly. Agent actions route through a governed gateway where identity, policy, and logging are enforced consistently. Without this pattern, agentic AI becomes operationally ungovernable. Decisions happen through chained tool calls that cannot be reconstructed or constrained after the fact.
VII.4. Rails Before Trains
The operational principle that separates governance architecture from governance theater is simple: build the rails before you run the trains.
Before deploying models and agents, build the governance infrastructure. Gateways that route decisions through governed paths. Policy engines that evaluate constraints at runtime. Identity boundaries that limit blast radius. Decision rights that specify who can authorize what. Audit capture that records evidence automatically. This infrastructure must exist before the first model goes live, not after the first incident.
The most common anti-pattern in enterprise AI today is scattering governance across components that cannot enforce it. Prompts instruct models not to do something, yet provide no mechanism to prevent it. Developer discipline assumes teams will remember to log decisions. Slide decks memorialize a committee’s approval, which is never revisited. None of these scales. None of it survives vendor updates, tool sprawl, or agentic autonomy.
CTRS turns governance into a deployable system with clear invariants:
- If a decision is high-risk, it must run through the governed path.
- If a decision is governed, it must generate audit-ready evidence.
- If a system changes, it must trigger version controls and reassessment.
The infrastructure enforces these rules regardless of whether individual teams remember them, whether developers follow guidelines, or whether management is paying attention on any given day. That is what makes governance operational rather than aspirational.
For deeper treatment of these concepts, see “Decision Centric AI: Bridging Predictive Gaps” for the complete Decision Velocity framework, “Enterprise AI Version Drift: The Hidden Risk & How to Fix It” for Trust Layer implementation patterns, and “Model Context Protocol (MCP): The Integration Fabric for Enterprise AI Agents” for MCP Gateway architecture.
VIII. Decision Rights Allocation
Another reason for enterprise AI failures is unclear authority. Who can let AI act? Who must review? Who can override? Who is accountable when outcomes are wrong?
This is why decision rights serve as the link between governance as a structured framework and governance in practice. Without clear decision rights, everything reverts to superficial compliance. Policies are in place, but nobody can specify who truly owns each decision. In incident postmortems, a common theme emerges: responsibility was shared among several teams, yet no one took ownership of the final decision.
VIII.1. Why Traditional Accountability Models Fail
RACI was built for projects where decisions happen at human speed, actions are discrete, and responsibility can be assigned in static charts. AI breaks all three assumptions.
AI decisions happen in milliseconds, at scale. By the time a traditional framework would route something for review, the system has made thousands more decisions. Accountability becomes ambiguous when systems positioned as “advisory” are followed 98% of the time. Is the human truly accountable, or has the organization delegated the decision while keeping liability on paper? And static allocation fails because AI systems evolve continuously. Prompts change, retrieval corpora shift, models update, and tools are added. A RACI chart created at launch becomes obsolete faster than the system it governs.
VIII.2. Extending Accountability for AI
If organizations still want a RACI-style framework, they need two additional roles that classic governance ignores:
- Adversarial function: Responsible for continuously testing how the system can be manipulated through red teaming, prompt injection, tool abuse, and abuse-case design. Without this role, security testing happens once at launch and never again.
- Impacted parties function: Responsible for representing those who bear harm if the system fails. HR for employment systems. Patient safety for clinical systems. Consumer risk for lending and claims. Without this role, the people affected by AI decisions have no voice in governance.
These additions force two missing duties into the operating model: someone must continuously test for manipulation, and someone must represent those who bear consequences. But even extended accountability models are just role labels. What you need is a decision contract that controls autonomy.
VIII.3. The Decision Rights Matrix
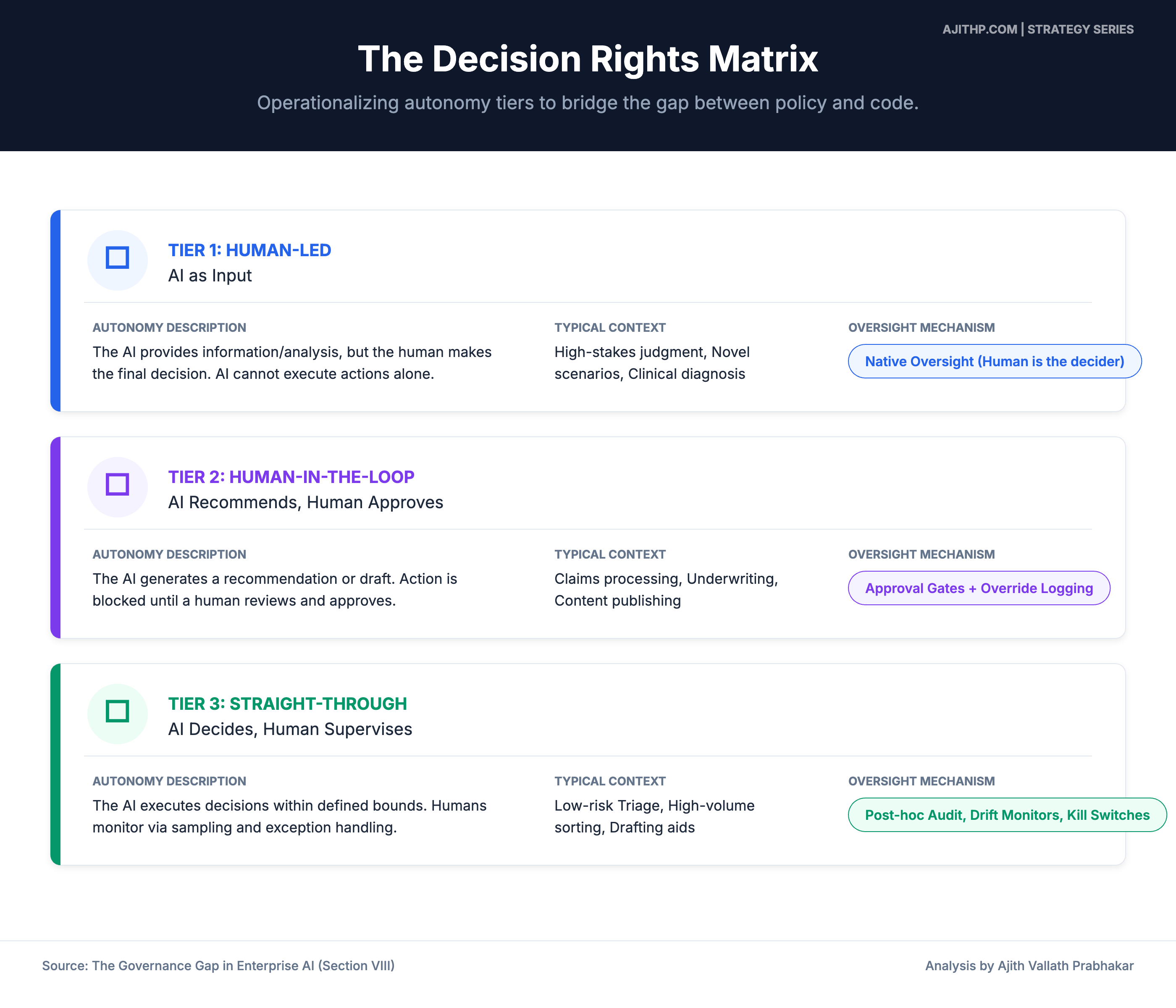
The replacement for traditional accountability frameworks is a Decision Rights Matrix that assigns autonomy and oversight based on risk and decision class.
Three tiers cover most scenarios
- Tier 1: Human-led, AI as input. The AI provides information, but the human makes the final decision. The system cannot determine outcomes on its own. This level is for decisions that require human judgment, with AI merely presenting relevant data or options.
- Tier 2: Human-in-the-loop. The AI provides a recommendation, but human approval is needed to finalize. Escalation procedures and override protocols must be clearly defined. This level is for decisions where AI manages routine cases, but humans must approve before proceeding with action.
- Tier 3: Straight-through processing. The AI makes decisions within set constraints. Humans supervise through monitoring, sampling, and handling exceptions instead of reviewing each decision. This level is suitable for high-volume, lower-risk decisions where checking every decision by humans would be impractical.
Tier assignment is a risk posture, not a moral stance. And Tier 3 is “no humans.” It is humans moving from approval to supervision, with precise intervention mechanisms when thresholds are breached.
A usable matrix includes risk tier, decision class, default autonomy, escalation triggers, and oversight mechanisms:
| Risk | Decision Class | Default Autonomy | Escalation Triggers | Oversight Mechanism |
| High | Credit approval, underwriting | Tier 2 or Tier 3 with tight bounds | Out-of-distribution applicant, low confidence, fairness anomaly | Approval for edge cases, audit sampling; and drift monitoring |
| High | Clinical triage, treatment support | Tier 1 or Tier 2 | Guideline contradiction, low confidence, novel presentation | Mandatory clinician review; override logging; safety board |
| Medium | Customer support policy guidance | Tier 2 | Policy uncertainty, retrieval mismatch | Human approval for exceptions; retrieval provenance required |
| Low | Internal drafting, summarization | Tier 3 | Sensitive data detected | Automated redaction; logging; periodic review |
VIII.4. Decision Rights as Code
Decision rights documented in slide decks are not decision rights enforced in production. CTRS closes that gap by expressing decision rights as a machine-enforced configuration.
decision_rights:
decision_id: credit_underwriting_v2
risk_tier: high
default_autonomy: tier2_hitl
allowed_models:
- model: "risk_score_gbm"
version: "2.4.1"
- model: "llm_explainer"
version: "gpt-5.2"
constraints:
max_auto_approval_amount_usd: 25000
confidence_threshold: 0.82
prohibited_inputs:
- "protected_class_attributes"
fairness_checks:
enabled: true
metrics:
- equal_opportunity_diff
- demographic_parity_diff
alert_threshold: 0.05
escalation:
triggers:
- type: out_of_distribution
- type: low_confidence
- type: fairness_anomaly
- type: conflicting_evidence
route_to: "underwriter_queue"
logging:
capture:
- identity
- input_features
- model_versions
- policy_version
- explanation
- final_decision
retention:
hot_days: 30
warm_days: 365
cold_years: 7
The YAML specifies the rules. The system enforces them at runtime.
VIII.5. Mapping to EU AI Act Article 14
EU AI Act Article 14 requires that high-risk systems be designed so humans can effectively oversee them. The keyword is not “human involvement.” It is effective, meaning the human role must be meaningful, competent, and capable of intervention.
This maps directly to the decision tiers. Tier 1 oversight is native because the human makes the decision. Tier 2 oversight is built into the approval gate, though organizations must guard against rubber-stamping. Tier 3 oversight requires explicit mechanisms: kill switches, throttles, rollback capabilities, exception routing, and audit sampling.
The compliance trap is pretending Tier 2 exists when it does not. If 99% of recommendations are auto approved, you have de facto Tier 3 under a Tier 2 label. Regulators will examine actual approval rates, review time, and override frequency. Documentation claiming human-in-the-loop means nothing if the data shows humans approve everything in seconds.
VIII.6. Case Study: The Epic Sepsis Model
In 2021, a study published in JAMA Internal Medicine evaluated Epic’s sepsis prediction model deployed across hundreds of hospitals. The model was designed to alert clinicians to early signs of sepsis, enabling quick intervention. However, the model missed 67% of sepsis cases while generating too many false positives, leading to alert fatigue among clinical staff.
But the deeper failure was not the model’s predictive performance. It was the governance surrounding its deployment.
The model influenced high-stakes clinical pathways, yet oversight design varied wildly across hospitals. Some sites treated alerts as mandatory review triggers. Others let them scroll past in busy workflows. Alert fatigue turned what was labeled a “recommendation” into background noise at some sites and de facto automation at others. When researchers tried to assess governance evidence, they found inconsistency everywhere: who could override alerts, how overrides were documented, and what monitoring existed differed by institution.
This is what happens when a high-risk AI system ships without a decision rights architecture. Each deployment site made ad hoc choices about human authority, escalation, and oversight. No standardized decision contract existed. The “human-in-the-loop” label satisfied procurement and compliance reviews, but the loop was not designed.
Contrast this with clinical AI deployments that have worked. Clinicians retain explicit authority over final decisions. Alert thresholds are tuned per site to balance sensitivity against fatigue. Override pathways are defined and logged. Monitoring focuses on clinical outcomes, not just model metrics. The difference is not a better algorithm. It is an explicit decision design before deployment.
The lesson extends beyond healthcare. Without decision rights architecture, “human oversight” becomes a checkbox that satisfies no one when something goes wrong. The organization inherits liability while the system quietly makes decisions.
IX. Audit Trail Architecture
If governance is infrastructure, the audit trail is the evidence plane. It is what allows you to answer, with precision, the questions that matter in an examination or investigation. What happened? Which system version did it? What inputs did it see? What policy constraints were in force? Who approved, overrode, or escalated? Can you prove it was not tampered with?
Under the EU AI Act, high-risk systems must support automatic logging over the system lifecycle, and providers must retain automatically generated logs for at least six months, or longer if other laws require it. That is the legal forcing function. The architectural problem is building audit capability without turning your AI platform into a latency burden or a storage disaster.
IX.1. Four-Layer Audit Model

A practical audit trail isn’t simply about “saving all prompts.” Instead, it’s a structured event model that reconstructs decisions across four layers from start to finish.
- Layer 1: Identity. Capture caller identity, delegated identity for on-behalf-of scenarios, tenant and client context, authentication details, and the authorization decision explaining why this action was permitted.
- Layer 2: Input. Capture the user request, retrieved context with document identifiers and content hashes, features used in decision-making, tool outputs used as evidence, and sensitive data markers indicating where PII or PHI was present or redacted.
- Layer 3: Processing. Capture model identifiers, including provider, model name, and version. Capture the prompt template version and policy pack version. Capture tool calls with tool name, parameters, responses, and permission checks. Capture guardrail decisions showing what was blocked or allowed and why.
- Layer 4: Output. Capture the final model output or decision outcome, confidence scores (where applicable), human oversight events (including approvals, overrides, escalations, and aborts), and downstream actions (such as case updates, claim decisions, ticket resolutions, or messages sent).
The key is that the audit trail captures decision lineage, not just text. You need to reconstruct not only what the system said, but what it knew, what constraints applied, and what happened next.
IX.2. Async Logging Architecture
Writing detailed logs synchronously to durable storage within your request path can harm performance, leading teams to disable the audit trail when facing tight latency budgets. Under delivery pressure, this often becomes the first feature to be turned off.
The solution is a gateway-first, asynchronous pipeline:
AI Gateway → Event Queue → Audit Workers → Immutable Store + Search Index
Three goals should drive the design. Keep request-path impact to single-digit milliseconds by pushing heavy writes off the critical path. Achieve near-zero loss tolerance through idempotent writes, retries, and backpressure handling. Ensure forensic quality by making records tamper-evident, time-ordered, and reconstructable.
The patterns that work in practice share a common thread: do less in-line, prove more after the fact. Emit a compact event envelope during the request containing just identifiers and pointers, then enrich it asynchronously with full context. Use idempotency keys to prevent retries from creating duplicate records. Hash-chain event batches to create tamper-evident cryptographic proof that logs have not been modified after they were written.
One distinction matters more than most teams realize: operational telemetry and audit evidence are not the same thing. Developer logs help engineers debug. Compliance records help you survive regulatory examination. They serve different purposes, have different retention requirements, and should live in different stores. Mix them, and you will either over-retain debugging noise or under-retain compliance evidence.
IX.3. Tiered Storage Strategy
The EU AI Act sets a minimum retention baseline of six months for automatically generated logs, subject to other applicable laws. In regulated industries, you often retain longer due to sector-specific rules, litigation holds, and internal risk policy. Healthcare records may require seven years. Financial services may require longer, depending on the decision type.
A reference architecture uses tiers to balance cost, searchability, and compliance:
- Hot (0-30 days): Fast query access for incident response, dashboards, and real-time monitoring. Expensive storage, full indexing.
- Warm (1-12 months): Compliance sampling, investigations, and drift analysis. Moderate cost, selective indexing.
- Cold (multi-year): Long-tail regulatory and legal needs. Cheap storage, slower retrieval, minimal indexing.
Two requirements are non-negotiable. First, the compliance copy must be immutable. Once written, records cannot be modified or deleted. This is not a preference; it is what makes your logs admissible as evidence. Second, your indexing must make audit queries practical. If you cannot quickly search by decision, system version, policy version, user, risk tier, or outcome, you have a data lake, not an audit trail. And a trail you cannot search will fail you exactly when you need it most.
IX.4. Integration with Enterprise Risk Systems
Audit trails fail when they become isolated data lakes that only the AI team understands. The key is integration: feeding governance evidence into existing enterprise system uses.
Security operations need to see AI-related incidents alongside everything else. Route agent actions, anomalous tool use, and data egress signals to your SIEM. Risk management needs evidence that controls are functioning, not just documented. Feed decision outcomes and control activations into your risk register. Incident management needs automatic escalation when guardrails trigger or anomalies spike. Do not wait for someone to notice a problem buried in logs. And compliance teams need to verify evidence completeness without digging through raw data. Give them dashboards that show logging coverage, sampling results, and pointers to required documentation.
A simple test: if your audit trail cannot feed both your incident response and your compliance reporting, it will not survive a real examination.
IX.5. What Regulators Actually Examine
Across regulatory regimes, examiners request the same evidence patterns:
- A register of high-risk systems with sampled decision traces showing end-to-end lineage
- Proof that logging is automatic, consistent, and retained appropriately
- Change control records showing what changed, who approved, and whether reassessment was triggered
- Human oversight evidence showing where humans intervened, how often, and whether it was meaningful
Don’t consider audit trail as a compliance checkbox. It is what makes every other governance claim verifiable. Without it, your decision rights matrix is theory. Your policy-as-code is an assertion.
For a deeper treatment of observability in production AI systems, see “LLM Observability & Monitoring: A Strategic Guide to Trustworthy GenAI.“
X. 90-Day Implementation Roadmap

Most organizations fail at AI governance the same way they fail at enterprise architecture: they try to boil the ocean. They start with principles, committees, and multi-year programs. They end up with something that looks impressive but does not actually constrain real systems.
The alternative is simpler. Build a minimum viable governance foundation around one high-risk decision flow. I call this a “Money Decision”: a decision that directly drives financial exposure, legal liability, safety risk, or discriminatory harm if it fails. Not a chatbot. Not an internal drafting tool. A decision where failure has consequences.
In 90 days, you can build inventory that reflects reality, decision rights that are enforceable, audit infrastructure that produces real evidence, and a review mechanism that can scale.
X.1. Phase 1: Inventory and Triage (Weeks 1-4)
The goal is an inventory you can actually use, not a list of projects that makes leadership feel better.
Most inventories overlook half of the AI in the organization. They document internal models but ignore the SaaS platforms with AI quietly embedded. They miss entirely shadow AI: the tools employees access through corporate credentials that haven’t been approved. And they disregard agentic workflows still in labs or prototypes.
For each system, answer five questions:
- What decision does it influence?
- Who is affected?
- What is the default autonomy today?
- What data does it touch?
- Is it likely high-risk under the EU AI Act or sector rules?
Then triage into three categories:
- Red: High-risk decisions, agentic tool use, regulated data, unclear oversight
- Amber: Moderate impact, some controls, incomplete evidence
- Green: Low impact, internal drafting, no regulated decisions
Now select your pilot. Choose a Red decision flow that the business already relies on, where there is real financial or regulatory risk, and where someone owns the workflow and can make decisions. Do not pick a toy pilot. Pick something that truly matters.
A common mistake is treating inventory as documentation rather than actively discovering actual usage. You need to seek out vendor AI and shadow applications actively. An accurate inventory that overlooks real system behavior will not stand up when an auditor questions which systems truly influence customer decisions.
X.2. Phase 2: Decision Rights and Design (Weeks 5-8)
The goal is to convert governance from theory into enforceable decision contracts.
Begin by mapping the decision flow for your pilot project. Follow the inputs through processing steps to outputs and subsequent actions. Pinpoint where AI impacts the workflow. Record where humans currently review or override decisions, if applicable.
The next step is to build a decision rights matrix, including tier classification, default autonomy, escalation triggers, override authority, and sampling requirements. This process solidifies governance. Without clear decision rights for any decision, effectively scaling governance across the enterprise becomes unrealistic.
Next, encode your initial policy-as-code version by starting with the minimum constraints: permitted data inputs, masking rules, approved tools, confidence thresholds for routing uncertain cases, and logging requirements.
Finally, prepare a technical file aligned with Annex IV for the pilot, even if you’re outside the EU. This process ensures you document the purpose, boundaries, data governance, risk mitigation, human oversight, and change management, which are essential regardless of jurisdiction.
Phase 2 shifts from committee discussions to system design. For further insights on decision-focused architecture, refer to “Decision Centric AI: Bridging Predictive Gaps.“
X.3. Phase 3: Technical Controls (Weeks 9-12)
The goal is to deploy the minimal infrastructure that makes governance real at runtime.
Start by establishing a governed AI gateway that routes all pilot AI calls through a single, controlled path. This path should enforce identity verification, tool allowlists, input filtering, policy checks, and standardized logging. Maintain a single, consistently governed route with no exceptions.
Next, develop an audit logging pipeline employing the asynchronous architecture described in Section IX. Capture events at the gateway, process them with audit workers, store the data immutably with searchable indexes, and display coverage and anomalies on dashboards.
Third, establish a Decision Review Board. Remember, this should not be a monthly steering committee, but a small, operational group that meets weekly or biweekly. Its purpose is to review escalations, override patterns, drift signals, and proposed changes. Keep the focus on practical review rather than formality.
Fourth, enforce vendor requirements for the pilot. If vendor AI is involved, require architectural evidence, route through your gateway, and maintain independent logs. Do not outsource governance to vendor assurances.
X.4. What to Deprioritize
Governance fails when the scope expands faster than the enforcement capability. In 90 days, deliberately ignore four things.
- Global ethics policies without enforcement. If you are unable to encode it, then it isn’t governance; rather, it is marketing.
- Big-bang GRC platform selection. Buy tools after you know what evidence you need. Buying first means configuring around capabilities you have not validated.
- Low-risk chatbots and drafting tools. Start with the Money Decision. Once you have a working template, extend it to lower-risk systems.
- Committee proliferation. One operational review board tied to one governed decision beats five committees with no control plane.
X.5. The 90-Day Test
By the end of 90 days, you should be able to accomplish something most organizations cannot.
Reconstruct a real high-risk decision from start to finish. Demonstrate who owned it, what policy constraints applied, how it evolved over time, and how oversight functioned in practice.
This becomes your template. Then scale up: expand the inventory, onboard more decision flows, and increase coverage across vendors and agents. The 90-day foundation isn’t the final goal; it’s proof that the governance architecture works before you commit to an enterprise-wide rollout.
XI. The Case for Chief Decision Officer
You can establish a robust governance framework and still fall short if ownership is scattered. In many organizations, AI governance is theoretically everyone’s duty but practically no one’s practice.
This is the accountability vacuum. When AI fails, it is unclear who owns the decision design, the oversight model, and the quality of outcomes.
XI.1. The Accountability Vacuum
Observe the current division of responsibilities: the CIO oversees platforms and delivery speed; the CISO manages security controls; the Chief Data Officer handles data governance and quality; the Head of AI is responsible for model development; and Compliance manages policies and regulatory engagement. Business units are accountable for outcomes but do not have technical control.
Each function has an important responsibility. None has the responsibility for the issue regulators and boards increasingly focus on: the quality and governance of decisions made or influenced by AI.
This isn’t just semantics; fragmented ownership leads to predictable failures.
Decision rights differ across business lines depending on the system creators. Human oversight is documented, but its effectiveness remains unverified. Vendors are onboarded using procurement standards that often overlook governance. Audit records are incomplete as logging relies on local discipline standards. When incidents happen, postmortems usually turn into blame-shifting exercises, with everyone deflecting responsibility.
The outcome is large-scale compliance theater. Policies are in place, committees convene, but decision governance stays weak.
XI.2. The Role Defined
The Chief Decision Officer is not just a renamed Chief Data Officer. Instead, their role is defined by a single mandate: to oversee the governance of AI-influenced decisions from start to finish.
That means five responsibilities:
- Own the decision rights architecture. Establish and maintain the Decision Rights Matrix. Approve autonomy tiering for high-risk decisions. Ensure escalation and override pathways actually work.
- Chair the Decision Review Board. Run an operational forum focused on evidence, exceptions, drift, and incidents. Drive corrective action, not policy revisions.
- Own governance coverage. Maintain a decision-centric inventory of AI systems across internal, vendor, and shadow sources. Prioritize coverage expansion based on exposure, not politics.
- Define vendor requirements. Set minimum architectural and audit criteria for vendor AI systems that touch regulated decisions. Ensure procurement enforces gateway routing and independent logging.
- Coordinate regulatory defense. Ensure technical files exist for high-risk systems. Ensure evidence is reconstructable on demand. Work with legal on defensibility, not just documentation.
This is not just another layer; it is a consolidation of decision ownership that currently lacks a designated place.
XI.3. Where the Role Reports
Where the role sits matters more than the title.
If the Chief Decision Officer reports to the CIO, the role becomes captive to delivery priorities. If it reports to the Chief Data Officer, it becomes a data governance extension. If it reports to Compliance, it risks becoming policy-heavy and delivery-light.
The CDO should report directly to the CEO or COO, as AI decisions are both operational and critical to the business. There should be a dotted line to the Chief Risk Officer or Chief Compliance Officer to emphasize the importance of regulatory defensibility. Additionally, the CDO should work closely with the CIO, CISO, and business leaders.
The objective is to position the role as decision governance, not IT governance or compliance bureaucracy.
XI.4. How to Measure It
Here are the five KPIs that should be associated with the CDO that align with what boards and regulators actually care about:
- Decision Velocity. Time from insight to decision to action for governed flows. The goal: governance speeds deployment by reducing rework and uncertainty.
- Override Rate. Percentage of AI recommendations overridden by humans, tracked by decision class. The goal: detect rubber-stamping when rates are too low, or model instability when rates are too high.
- Escalation Volume. Count and rate of decisions routed to human review due to low confidence, anomalies, or fairness flags. The goal: ensure triggers are tuned and meaningful.
- Governance Coverage. Percentage of AI decision flows mapped into the Decision Rights Matrix and routed through the governed gateway. The goal: reduce the ungoverned AI surface area, especially vendor- and shadow-AI.
- Audit Readiness. Completeness of technical files and evidence for sampled high-risk decisions. The goal: reconstruct any decision end-to-end on demand.
These KPIs are operational by design. They reward architecture and enforcement, not committee activity.
XI.5. Why Now
EU AI Act Article 14 mandates meaningful human oversight, meaning someone must oversee decision design and provide evidence. As a result, state laws and sector regulators view AI decisions as issues of consumer harm and discrimination, requiring apparent oversight. The rise of agentic AI raises the risk that governance issues could lead to security and integrity breaches.
Even if you do not create the title, the function is still necessary. The key decision is whether it should serve as a clear, authoritative role or as a scattered responsibility that only becomes apparent during an incident.
For a deeper treatment of decision-centric architecture and the Chief Decision Officer mandate, see “Decision Centric AI: Bridging Predictive Gaps.”
XII. Conclusion: Architecture Before Policy

This pattern recurs across various industries. Companies invest substantially in AI, and leadership launches governance initiatives. Committees are established, policies are drafted, but regulators often find persistent issues: ambiguous decision rights, lack of comprehensive audit trails, vendor AI operating beyond governance limits, and nominal human oversight. The core issue isn’t the absence of policies but the lack of a solid structural framework.
The Regulatory Reality
The EU AI Act is in force, with prohibited practices effective February 2025 and high-risk system requirements following in August 2026. US states are building a patchwork of disclosure, anti-discrimination, and impact assessment requirements. Colorado, California, Illinois, and New York City have already moved. Others will follow. Sector regulators in banking, healthcare, and insurance are extending existing frameworks to cover AI-influenced decisions, and they expect the same evidence discipline they require for traditional model risk.
Agentic AI accelerates the timeline. Systems that act autonomously create attack surfaces that did not exist in prompt-and-response architectures. Goal hijacking, tool misuse, memory poisoning, and inter-agent manipulation are not theoretical risks. They are documented vulnerabilities that security teams must address now.
The Architecture Response
Decision rights must be explicit and enforceable during runtime, not just documented in slides and overlooked. The Trust Layer must prevent version drift by verifying policy currency before retrieval, not after incidents occur. Agent orchestration should route through controlled pathways with tool allowlists, identity controls, and containment boundaries. Audit trails need to automatically capture decision lineage instead of relying on local logging practices. Additionally, someone must own decision quality end-to-end, with authority aligning with accountability.
This is what CTRS offers: a control plane for AI-influenced decisions that turns governance into an operational process rather than just an aspiration.
The Path Forward
You don’t need a multi-year transformation program; instead, focus on 90 days and a single high-risk decision process. Start by building an inventory that accurately reflects your environment, including vendor AI and shadow systems. Clearly define decision rights for your pilot project and formalize them as policies. Implement a governed gateway to enforce controls during operations. Set up an audit pipeline that generates reconstructable evidence.
Establish a Decision Review Board that meets weekly rather than quarterly. After 90 days, you’ll be able to reconstruct a real decision, who owned it fully, the constraints in place, what changed, and how oversight functioned, creating a template for scaling efforts.
The Choice
Every enterprise deploying AI faces the same choice. Build governance architecture now, when you control the timeline and can learn from a pilot. Or build it later, under regulatory pressure, after an incident has defined the scope for you.
The organizations that treat governance as infrastructure will move faster, not slower. They will deploy with confidence because decision rights are clear. They will pass examinations because evidence exists by design. They will onboard vendors without inheriting uncontrolled risk. And they will scale agentic systems because the guardrails are already in place.
The architecture gap can be closed. The question is whether you do it on your own terms or on a regulator’s terms.
Read more on this series
For deeper exploration of the frameworks and concepts in this article:
- “Decision Centric AI: Bridging Predictive Gaps” covers Decision Velocity, the 4D framework, and the Chief Decision Officer mandate.
- “Enterprise AI Version Drift” explains Trust Layer architecture and why RAG alone is insufficient for compliance.
- “Model Context Protocol (MCP): The Integration Fabric for Enterprise AI Agents” provides the architectural patterns for governed agent orchestration.
- “LLM Red Teaming 2025: A Practitioner’s Playbook” covers the threat taxonomy and security testing approaches for agentic systems.
- “LLM Observability & Monitoring: A Strategic Guide to Trustworthy GenAI” addresses production monitoring, telemetry design, and drift detection.
References
- Verizon. “2025 Data Breach Investigations Report.” https://www.verizon.com/business/resources/reports/dbir/
- Stanford CodeX. “AI Vendor Contract Analysis.” https://law.stanford.edu/codex-the-stanford-center-for-legal-informatics/
- European Commission. “EU AI Act.” https://artificialintelligenceact.eu/the-act/
- Colorado General Assembly. SB 24-205. https://leg.colorado.gov/bills/sb24-205
- NAIC. “Model Bulletin on Use of AI Systems by Insurers.” https://content.naic.org/sites/default/files/inline-files/2023-12-4%20Model%20Bulletin_Artificial%20Intelligence%20Systems.pdf
- FDA. “Artificial Intelligence and Machine Learning (AI/ML)-Enabled Medical Devices.” https://www.fda.gov/medical-devices/software-medical-device-samd/artificial-intelligence-and-machine-learning-aiml-enabled-medical-devices
- EY Center for Board Matters. “How Fortune 100 Boards Are Approaching AI Oversight.” https://www.ey.com/en_us/board-matters/how-fortune-100-boards-are-approaching-ai-oversight
- McKinsey & Company. “The State of AI in 2024.” https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
- Fortinet. “2025 Cybersecurity Skills Gap Report.” https://www.fortinet.com/resources/reports/cybersecurity-skills-gap-report
- European Commission. “EU AI Act.” https://artificialintelligenceact.eu/the-act/
- Wong et al. “External Validation of a Widely Implemented Proprietary Sepsis Prediction Model.” JAMA Internal Medicine, 2021. https://jamanetwork.com/journals/jamainternalmedicine/fullarticle/2781307
- Zhang et al. “Rethinking Human-AI Collaboration in Complex Medical Decision Making: A Case Study in Sepsis Diagnosis.” CHI ’24, 2024.
- Verizon. “2025 Data Breach Investigations Report.” https://www.verizon.com/business/resources/reports/dbir/
- Stanford CodeX. “AI Vendor Contract Analysis.” https://law.stanford.edu/codex-the-stanford-center-for-legal-informatics/
- Fortinet. “2025 Cybersecurity Skills Gap Report.” https://www.fortinet.com/resources/reports/cybersecurity-skills-gap-report
- Veracode. “2025 GenAI Code Security Report.” https://www.veracode.com/resources/state-of-software-security
- BigID. “AI Risk & Readiness Report 2025.” https://bigid.com/resources/
- Zscaler. “2024 AI Security Report.” https://www.zscaler.com/resources/industry-reports
- Crunchbase. “2024 AI Funding Report.” https://www.crunchbase.com/
- European Commission. “EU AI Act: Full Text.” https://artificialintelligenceact.eu/the-act/
- European Commission. “EU AI Act: Annex III High-Risk AI Systems.” https://artificialintelligenceact.eu/annex/3/
- European Commission. “EU AI Act: Annex IV Technical Documentation.” https://artificialintelligenceact.eu/annex/4/
- European Commission. “EU AI Act: Article 26 Deployer Obligations.” https://artificialintelligenceact.eu/article/26/
- European Commission. “EU AI Act: Article 27 Fundamental Rights Impact Assessment.” https://artificialintelligenceact.eu/article/27/
- European Commission. “EU AI Act: Articles 51-56 General Purpose AI Models.” https://artificialintelligenceact.eu/chapter/5/
- European Commission. “Modifying AI Under the EU AI Act.” https://artificialintelligenceact.eu/modifying-ai-under-the-eu-ai-act/
- Med Envoy Global. “The EU AI Act and Notified Bodies.” https://medenvoyglobal.com/blog/the-eu-ai-act-and-notified-bodies/
- Board of Governors of the Federal Reserve System. “SR 11-7: Guidance on Model Risk Management.” April 4, 2011. https://www.federalreserve.gov/supervisionreg/srletters/sr1107.htm
- Office of the Comptroller of the Currency. “OCC Bulletin 2011-12: Sound Practices for Model Risk Management.” April 4, 2011. https://www.occ.gov/news-issuances/bulletins/2011/bulletin-2011-12.html
- Consumer Financial Protection Bureau. “CFPB Acts to Protect the Public from Black-Box Credit Models Using Complex Algorithms.” May 26, 2022. https://www.consumerfinance.gov/about-us/newsroom/cfpb-acts-to-protect-the-public-from-black-box-credit-models-using-complex-algorithms/
- U.S. Food and Drug Administration. “Artificial Intelligence and Machine Learning (AI/ML)-Enabled Medical Devices.” https://www.fda.gov/medical-devices/software-medical-device-samd/artificial-intelligence-and-machine-learning-aiml-enabled-medical-devices
- U.S. Food and Drug Administration. “Marketing Submission Recommendations for a Predetermined Change Control Plan for Artificial Intelligence/Machine Learning-Enabled Device Software Functions.” April 2023. https://www.fda.gov/regulatory-information/search-fda-guidance-documents/marketing-submission-recommendations-predetermined-change-control-plan-artificial
- National Association of Insurance Commissioners. “Model Bulletin: Use of Artificial Intelligence Systems by Insurers.” December 2023. https://content.naic.org/sites/default/files/inline-files/2023-12-4%20Model%20Bulletin_Artificial%20Intelligence%20%28AI%29%20Systems.pdf
- Colorado General Assembly. “Senate Bill 21-169: Concerning Unfair Discrimination in Insurance Practices.” https://leg.colorado.gov/bills/sb21-169
- Colorado General Assembly. “Senate Bill 24-205: Colorado Artificial Intelligence Act.” https://leg.colorado.gov/bills/sb24-205
- Colorado Attorney General. “Colorado AI Act Implementation.” https://coag.gov/ai/
- California Civil Rights Council. “Modifications to Employment Regulations Regarding Automated-Decision Systems.” https://calcivilrights.ca.gov/employment/
- Illinois General Assembly. “HB 3773: Illinois Human Rights Act Amendment.” https://www.ilga.gov/legislation/BillStatus.asp?DocNum=3773&GESSION=103&GA=103&DocTypeID=HB
- New York City Department of Consumer and Worker Protection. “Automated Employment Decision Tools.” https://www.nyc.gov/site/dca/about/automated-employment-decision-tools.page
- Bloomberg Law. “State AI Legislation Tracker.” https://www.bloomberglaw.com/product/blaw/document/X9Q5EO7C000000
- OWASP. “Agentic Security Initiative.” https://genai.owasp.org/agentic-security/
- OWASP. “Top 10 for Agentic Applications.” https://genai.owasp.org/resource/owasp-top-10-for-llm-agentic-applications/
- NIST. “AI Risk Management Framework: Agentic AI Considerations.” https://www.nist.gov/itl/ai-risk-management-framework
- NIST National Vulnerability Database. “CVE-2025-32711.” https://nvd.nist.gov/vuln/detail/CVE-2025-32711
- ServiceNow Security Advisory. “Agent Discovery Security Considerations.” November 2025.
- Embrace The Red. “IDEsaster: AI Coding Assistants Security Analysis.” December 2025. https://embracethered.com/blog/posts/2025/idesaster-agent-security-research/
- Microsoft Security Response Center. “Microsoft 365 Copilot Security Updates.” June 2025.
- Prabhakar, Ajith Vallath. “LLM Red Teaming 2025: A Practical Playbook for Securing Generative AI Systems.” AjithP.com, July 13, 2025. https://ajithp.com/2025/07/13/red-teaming-large-language-models-playbook/
- European Commission. “EU AI Act: Article 14 Human Oversight.” https://artificialintelligenceact.eu/article/14/
- Wong, A., et al. “External Validation of a Widely Implemented Proprietary Sepsis Prediction Model in Hospitalized Patients.” JAMA Internal Medicine, 2021. https://jamanetwork.com/journals/jamainternalmedicine/fullarticle/2781307
- European Commission. “EU AI Act: Article 12 Record-Keeping.” https://artificialintelligenceact.eu/article/12/
- European Commission. “EU AI Act: Article 19 Logs.” https://artificialintelligenceact.eu/article/19/
Discover more from Ajith Vallath Prabhakar
Subscribe to get the latest posts sent to your email.
You must be logged in to post a comment.