Audio Overview
Executive Summary
Despite billions invested in artificial intelligence, up to 90% of enterprise initiatives fail to deliver meaningful value, stalling in “pilot purgatory.” This failure is not technical; it is a strategic misalignment. Organizations have become experts at building predictive models but remain amateurs at making and executing decisions based on the intelligence those models provide. The result is a portfolio of sophisticated, expensive shelfware with no discernible impact on the P&L.
This article presents a playbook to correct this course. It argues for a fundamental shift from a model-centric strategy, which measures success by technical accuracy, to a decision-centric strategy, which measures success by the quality and speed of actions taken. We diagnose the root causes of failure—broken decision architectures, diffuse ownership, and workflow inertia—and provide a comprehensive framework to transform AI from a cost center into a scalable value engine.
This framework introduces a new operating model built around Decision Intelligence, a technology backbone called the Decision Factory, and a new North Star metric for the boardroom: Decision Velocity. By architecting AI around auditable, governed, and accountable decisions, leaders can finally bridge the gap between prediction and profit, creating a compounding competitive advantage that is both measurable and defensible.
The AI Paradox: Why Enterprises Fail at AI
A major bank’s fraud detection model reaches 97.3% accuracy, but the bank still loses $2 million every month. Why? Because no one has clear authority to block transactions prompted by the model’s alerts. This highlights a $50 billion blind spot in enterprise AI. While organizations are refining their predictive capabilities, they are failing to act on those predictive decisions.
Across various industries, this is a recurring paradox. Companies have invested billions in predictive analytics and generative AI, anticipating significant change, yet the outcomes are still modest. Failure at scale: A recent MIT study found that 95% of enterprise AI initiatives fail to meet objectives. Gartner and McKinsey confirm that 70-90% stall in “pilot purgatory.”
- The AI graveyard: Proof-of-concepts that don’t scale, copilots employees never adopt, and advanced models that remain expensive shelfware.
- Case snapshots:
- Ford: Built predictive maintenance models that could forecast failures three weeks ahead, but projects stalled due to workflow integration challenges.
- Accenture: Ran over 300 generative AI pilots for clients, most stuck at the proof-of-concept stage with unclear business outcomes.
- MD Anderson & IBM Watson Oncology: After a $60M investment, the system was shelved due to unsafe recommendations and clinical workflow misfit.
- The ROI gap: Despite adoption, over 80% of companies report no profit lift. 42% abandoned most projects, and 97% of executives struggle to prove business value from generative AI.
At the heart of this paradox is a strategic misalignment. Companies focus heavily on technical precision but often overlook the organizational capability to execute. For example, a churn prediction model might flag at-risk customers, but without coordination between sales and marketing to act on those insights, the predictions go unused.
Worse, the traditional model-centric approach often produces a negative total cost of ownership (TCO): up to 70–90% of AI spending is wasted on models that never operationalize.
Enterprise AI isn’t failing due to weak models. Its failure stems from broken decision-making, ownership is scattered, workflows are misaligned, and governance is lacking. Without bridging the gap between predictions and actions, organizations risk remaining stuck in pilot limbo, contributing to the AI graveyard.
Root Cause: Broken Decision Architectures
The common failure of enterprise AI isn’t due to weak algorithms. Instead, it stems from structural flaws in decision-making processes within organizations. AI highlights these issues because it produces intelligence at machine speed, while enterprises remain locked in slow, politicized, and fragmented in their decision-making processes.
Poor Problem Definition (Shiny Object Syndrome)
One of the most common pitfalls is starting with the wrong question. Organizations pursue AI for hype or optics (“let’s use AI for customer engagement”) without defining a high-value decision, the owner, or success metrics. Data science teams often optimize for technically interesting but strategically irrelevant problems, leading to shelfware rather than business impact.
Siloed Pilots
AI projects frequently begin as fragmented experiments across departments. For example, marketing may create customer segmentation models, while finance tests anomaly detection, and IT deploys copilots. Without enterprise-level integration, these initiatives remain disconnected. Even AI Centers of Excellence can worsen the problem, producing prototypes in isolation. Pilots get celebrated internally but never scale, fueling pilot purgatory.
Workflow Inertia
Even when models work technically, organizations stumble on cultural and process alignment. Leadership often forces AI into old workflows rather than redesigning processes to exploit its capabilities. Analyst Benedict Evans describes it: enterprises “make a new tool fit their old way of working,” when the real value comes from “changing the work to fit the tool.” Middle managers resist change to KPIs, and regulated industries add further risk aversion. The result: AI stays in “safe zones,” never transformative.
Diffuse Responsibility
When projects stall, leaders blame surface-level issues. But poor data is a symptom of weak data governance. Skills gaps are a symptom of a missing strategy. The most pervasive pattern is the diffusion of responsibility: “everyone owns the decision until it breaks.” Without a single point of accountability, AI insights drift in a limbo of committee meetings and endless debate.
Unowned Decisions & Latency
Many key decisions fall into governance gaps. Marketing assumes that Sales will act on churn predictions; Sales assumes that Customer Success will take care of it. Without explicit ownership, opportunities die. Meanwhile, AI operates in milliseconds, but approvals take days or weeks. Fraud models neutralize competitive advantage when bureaucracy stalls execution. This mismatch between machine speed and human delay erases value.
Committee Paralysis
Complex decisions involve multiple stakeholders with veto power. Valuable AI outputs are trapped in consensus cycles. In one insurance pilot, an underwriting AI produced sound recommendations, but they spent months in steering committees, debated endlessly, and were never adopted. Decisions don’t fail technically; they fail politically.

The Speed Mismatch
Traditional processes obscure inefficiencies because delays blend into background noise. AI highlights them brutally because predictions from AI arrive instantly, but organizations can’t act. A churn model is useless if retention campaigns require weeks of approvals. AI doesn’t just fail to accelerate decisions; however, it reveals that decision-making is the enterprise bottleneck.
AI is not exposing technical flaws but structural ones. Unless organizations redesign decision architectures, such as clarifying ownership, eliminating latency, and aligning workflows, AI will continue to produce insights that enterprises are structurally incapable of acting upon.
Generative AI: Scaling Dysfunction or Scaling Value?
Generative AI entered the enterprise as a promise of transformation. With large language models (LLMs), copilots, and autonomous agents, leaders imagined decision-making that could be scaled, accelerated, and democratized. Instead, it has often deepened existing dysfunctions by amplifying ambiguity, surfacing governance gaps, and creating new regulatory liabilities.
From Promise to Stalled Reality
Most enterprises began with horizontal assistant use cases, such as summarizing meetings, drafting emails, and generating code snippets. These projects were easy to launch and showcased LLM capability. Yet the value rarely appeared in the P&L; “hours saved” metrics didn’t translate into financial outcomes.
The real opportunity of AI lies in domain-specific decision workflows. Finance copilots could review loan documents to identify compliance risks. Healthcare copilots might combine guidelines and patient histories to assist treatment decisions. Retail copilots can link supply, demand, and logistics for real-time adjustments. While these functions directly impact revenue, risk, and compliance, they often face challenges in scaling. Interestingly, the main obstacles are organizational rather than technical, caused by complex integration with legacy systems, regulatory demands for traceability, and unclear decision rights.
This explains why most executives do not expect widespread enterprise deployment of generative AI before 2026, despite its rapid rise in mainstream awareness. The paradox of generative AI is that, although it is the fastest technology to capture public attention, it remains one of the slowest to deliver enterprise ROI.
Fragmented Context and Hallucinations
Generative AI’s strength is producing coherent responses from extensive data. However, in enterprises, data is fragmented across SharePoint sites, CRMs, and personal drives. An LLM operating with only partial context is prone to hallucinations (Confident answers unsupported by facts). In a consumer setting, a hallucination is a nuisance. In an enterprise, it can be catastrophic: a legal copilot suggesting a non-existent precedent, or a compliance assistant fabricating a rule.
The Air Canada case is a turning point: the airline’s chatbot invented a refund policy, and the court held the company responsible. The precedent is clear. The liability rests with the enterprise, not the model. With enterprise data scattered across SharePoint, CRMs, and personal drives, fragmented context multiplies the risk of hallucination. Employees often cannot distinguish between fact and fabrication, raising the risk of misinformation becoming operationalized.
The RAG Reliability Trap
To combat hallucinations, enterprises are rapidly adopting Retrieval-Augmented Generation (RAG), where models ground their responses in enterprise knowledge bases, and vendors market RAG as the solution to boost enterprise adoption.
However, RAG reveals a deeper organizational problem: most organizations lack a single source of truth. Policies are duplicated across departments, product documentation conflicts with sales decks, and compliance rules evolve faster than repositories are updated. When an LLM retrieves multiple conflicting documents, which one governs the decision? Without clear governance, RAG accelerates confusion instead of resolving it.
The reliability trap is this: grounding improves outputs only if the organization itself is grounded. RAG cannot solve governance problems; it only surfaces them faster.
The Agentic Dilemma: Autonomy Without Accountability
If copilots represent today’s tools, autonomous agents are tomorrow’s promise. These systems can not only generate text but also act, such as rerouting shipments, freezing payments, and adjusting inventory. They offer exponential productivity gains by managing end-to-end workflows.
But this introduces another structural dilemma: autonomy without accountability.
- The Promise: Imagine a supply chain agent rerouting shipments proactively when a port delay is detected, or a finance agent instantly freezing suspicious payments before fraud occurs.
- The Pitfall: Now imagine that same agent incorrectly freezing legitimate payments or rerouting shipments unnecessarily, causing financial losses and eroding customer trust. Who is accountable when the agent is wrong?
In practice, agents repeatedly stall because enterprises force human checkpoints at every critical step, such as a manager must approve the expense, and a compliance officer must validate the transaction. The result is a semi-automated bottlenecked by approvals. This is not a technical immaturity but a governance void. Without clear decision rights, escalation paths, and override mechanisms, enterprises don’t trust agents enough to let them act. As AI researcher Andrej Karpathy warns, enterprises must “keep AI on a leash.” Autonomy cannot precede governance.
Compliance and Regulatory Risks
Generative AI doesn’t just surface operational issues; it magnifies regulatory exposure. Regulators in financial services, healthcare, and the EU AI Act are moving from a focus on model explainability to decision accountability. Enterprises that cannot show who authorized an action, what evidence supported it, and how overrides were handled face material compliance risk.
Generative AI can scale value only when it is embedded into decision-centric workflows with robust governance. Without accountability, clear decision rights, and integration into enterprise processes, it risks scaling dysfunction at machine speed.

Predictions vs. Decisions: The Core Dichotomy
Enterprise AI often confuses prediction with decision-making. This confusion is at the heart of why so many projects stall in pilot purgatory.
- Predictions are probabilities. They inform the likelihood of an event: a customer likely to churn, a transaction flagged as fraud, or a machine part predicted to fail. Predictions are informative but passive.
- Decisions are commitments. They involve taking an action: offering a retention incentive, blocking a payment, or scheduling maintenance. Decisions carry costs, risks, and consequences.
Why This Distinction Matters
A churn model with 90% accuracy is useless if there is no process or authority to intervene. Conversely, even a moderately accurate model, when embedded in a decision workflow, can generate significant ROI.
This distinction has critical implications for executives:
- Integration beats accuracy. A slightly less accurate model that is acted upon is more valuable than a perfect model that sits unused.
- Decision design matters. Trade-offs between false positives and false negatives must be explicitly built into the decision process.
- Latency defines competitiveness. Real-time decisions (e.g., fraud blocking) require decisions measured in milliseconds, not days.
- Adoption is the real KPI. Predictions must be trusted, owned, and acted upon; otherwise, they are just noise.
Predictions inform. Decisions commit. Only the latter creates ROI.
The Decision Intelligence Framework
Decision Intelligence (DI) is the discipline of turning information into better actions. Rather than starting with models or data, DI begins with the decision: its objectives, owner, constraints, and acceptable risk. It provides a shared language for executives, operators, and technologists, reframing AI from a technical experiment to a business capability.
Four Phases of the DI Framework
- Define the Decision
- Name the decision explicitly (e.g., Retail loan approval: approve/decline/escalate).
- Identify the accountable owner.
- Define objectives, risk tolerance, success criteria, and decision SLAs (speed requirements).
- Document the decision’s economic value: the upside of improved accuracy, speed, or consistency.
- Design the Decision Flow
- Inputs: the signals used, model outputs, business rules, policies, and knowledge bases.
- Decision logic: rules, thresholds, optimization, or agentic workflows that interpret inputs.
- Human-in-the-loop design: thresholds for auto-action, escalation conditions, and override procedures.
- Governance hooks: audit trails, explainability artifacts, and reason codes for decisions.
- Deploy the Action
- Trigger interventions in operational systems: a payment block, a customer call, or a supply chain reroute.
- Ensure traceability: every action is linked to the decision logic and inputs that drove it.
- Capture overrides explicitly; when humans disagree with AI, record the reason for future refinement.
- Defend and Learn
- Track decision KPIs: accuracy, latency, override rates, Straight-Through Processing (STP), and ROI per decision stream.
- Compare actual outcomes to intended objectives.
- Shorten the learning cycle by feeding insights into thresholds, models, and policies.
- Institutionalize a DecisionOps cadence (weekly/monthly reviews of overrides, drift, and KPIs).
Decision-Centric Maturity Model
Typically, maturity models have centered on infrastructure, such as the number of models in production or the complexity of MLOps pipelines. However, these metrics have a weak link to business results. In contrast, a decision-centric maturity model assesses how effectively an organization makes, executes, and manages its key decisions.

Roadmap: From 90 Days to Scale
- First 90 Days – Discover & Design
- Appoint a senior executive sponsor.
- Identify one “money decision” (high-impact, high-feasibility).
- Form a cross-functional DecisionOps team (business, tech, ops, compliance).
- Conduct a decision audit: map current flow, latency, cost, and error rates.
- First 6 Months – Deploy & Defend
- Codify the future state with a Decision Canvas documenting ownership, inputs, governance, and KPIs.
- Validate the new logic in a digital twin to de-risk deployment.
- Go live, establish a Decision Review Board, and track overrides as a learning source.
- First 12 Months – Scale
- Quantify ROI from the pilot (often 20–35% reduction in latency, payback in 12–18 months).
- Expand to the next 3–5 “money decisions” using the same playbook.
- Institutionalize the Decision Value Chain: discover, design, deploy, defend.
The goal is not to deploy the most models, but to make the most valuable decisions faster, consistently, and with measurable ROI. Decision Intelligence reframes AI success from technical accuracy to enterprise value.
Case Studies: Success and Failure in Action
While abstract frameworks are valuable, real-world examples clearly demonstrate the difference between model-centric and decision-centric approaches. These examples show that success or failure depends more on how effectively AI is integrated into the decision-making process than on the AI’s sophistication itself.
Failure
- IBM Watson for Oncology – Decision Integration Miss.
High-profile launch, strong algorithms, and extensive medical literature—yet real-world adoption fizzled. Recommendations clashed with local clinical practices, outputs were too vague, and there was no clean path into physician workflows or accountable ownership of actions. Key lesson: the absence of decision integration—not model quality—put the system on the shelf.
Successes
- Morgan Stanley Wealth Management – Copilot in the Flow of Work.
Advisors received a GPT-powered copilot embedded directly in their day-to-day tools, grounded on the firm’s knowledge base. It delivered research, compliance cues, and client-ready insights in real time—while advisors retained accountability. Adoption scaled because it improved decisions at the exact moment of decision-making. Key lesson: embed AI where decisions happen and align it with existing governance. - Insurance Claims – Decision Segmentation at Scale.
Carriers tiered claims into low/medium/high complexity, matching each tier to the right level of automation or human review. Straight-through processing jumped, cycle times fell, and adjusters focused on edge cases rather than routine work. Key lesson: design around decision classes; automate the routine, augment the complex. - Sepsis Detection in Hospitals – Decision Support in the EMR.
A sepsis risk model was surfaced inside the electronic medical record at the point of care, prompting timely interventions. Mortality dropped meaningfully because the guidance arrived within the normal workflow and physicians remained the final decision-makers. Key lesson: value comes from in-workflow decision support with clear accountability. - Global Retail Supply Chain – From Forecasts to Decisions.
A multinational retailer reframed “forecast accuracy” into a set of inventory, routing, and allocation decisions. It automated low-value moves, augmented mid-tier choices, and reserved executive time for high-stakes scenarios—cutting stockouts and logistics costs while improving resilience. Key lesson: treat operations as a portfolio of decisions; classify by value/risk and tune automation accordingly.
Across failures and wins, we are seeing a consistent pattern: AI delivers ROI when it’s architected around decisions, not when decisions are left implicit. Without taking action, predictions are just noise.
Building a Decision-Centric AI Strategy
Throughout the case studies, we observed that failures stemmed not from weak models but from a broken decision architecture. To move beyond pilots and stagnant solutions, leaders must prioritize a strategy focused on decisions. It builds on the Decision Intelligence Framework (Define → Design → Deploy → Defend) and its 90-day plan described earlier. Building this strategy depends on a clear financial case, a phased implementation plan, and a robust operating model.
What success looks like
Success here means the strategy is changing outcomes on your “money decisions,” not that models score higher. With the implementation of this strategy, within 12 months, you should see
- Decision Velocity up per stream (fraud, claims, credit, supply). Concretely: latency down ~20–35%, accuracy up to target bands, resilience stable under drift/outages, and governed coverage expanding.
- Auditable execution: every decision is replayable (inputs, policy/model versions, decision path, reason code, SLA).
- Financial impact reported: monthly ROI per decision stream in the exec pack.
Start with one money decision
Select a decision with real P&L or risk impact, has clear latency sensitivity, an actionable endpoint, and sufficiently reliable inputs to begin. A straightforward criterion: if Owner, SLA, and an Evidence Plan cannot be summarized on one page, it is not suitable as the initial decision.
| Criterion | Weight | Example Questions |
| P&L / Risk Impact | 5 | What’s the annualized upside/loss avoided at target performance? |
| Feasibility | 4 | Do we have signals, labels, policy, and a controllable action? |
| Latency Criticality | 3 | Does timeliness meaningfully change the outcome? |
| Ownership Clarity | 5 | Is there a single accountable decision owner? |
| Regulatory Sensitivity | 4 | Can we evidence each decision path and override? |
Create a table like this to evaluate the decision, and score candidates across impact (P&L, risk), feasibility(data, systems), latency need (real-time vs batch), governance criticality, and clear ownership.
The Leadership: The Rise of the Chief Decision Officer (CDO)
A transformation of this magnitude cannot be a part-time project delegated to an already overburdened executive. It requires a new center of gravity in the C-suite. The traditional C-suite structure is insufficient for the age of AI-powered decisions:
- The Chief Information Officer (CIO) is accountable for technology infrastructure and systems uptime.
- The Chief Data Officer is accountable for data quality, governance, and accessibility.
Neither is explicitly accountable for the quality and velocity of the decisions that are made using that technology and data. This creates the accountability vacuum where billions in AI investment disappear without a trace on the P&L.
To close this gap, we argue for the necessity of a Chief Decision Officer (CDO), a role accountable not for models or data, but for the portfolio of high-value decisions that drive the enterprise. The CDO is the executive who owns the enterprise-wide decision architecture and is ultimately responsible for its ROI.
The mandate of the Chief Decision Officer includes:
- Owning the Decision Value Chain: Championing and scaling the 4D framework across the organization.
- Managing the “Decision Inventory”: Maintaining a portfolio of the company’s “money decisions” and overseeing their continuous improvement.
- Chairing the Decision Review Board: Leading the governance process that ensures decisions are effective, compliant, and continuously refined based on real-world outcomes.
- Building the Operating Model: Sponsoring the creation and scaling of the cross-functional DecisionOps teams that execute the work.
- Reporting to the Board: Translating the work of the DecisionOps teams into a clear narrative of business value, reporting on decision-centric KPIs like decision velocity, straight-through processing rates, and ROI per decision stream.
The CDO is the crucial link between AI technology and business value, ensuring that the organization’s significant investments in data and models translate into a quantifiable, compounding decision advantage.
The operating model
A small, cross-functional DecisionOps squad treats each decision like a product with a roadmap, releases, guardrails, and KPIs.
- Decision Owner (business): sets objectives and risk posture, owns the SLA, and accepts trade-offs.
- Decision Engineer (product/ops): maintains the Decision Canvas, designs the human-in-the-loop experience, manages promotions (Shadow → Limited → Scale → Autonomy).
- Data/ML Lead: curates signals and models for the decision; monitors drift and benefit/cost at the decision level.
- Compliance/Risk Lead: encodes policy-as-code; ensures each decision emits a replayable evidence bundle.
- Platform/SRE: delivers SLOs, quotas/rate limits, and decision-aware observability.
- UX/Operator Lead (as needed): ensures overrides and escalations are ergonomic and consistently captured.
Rituals are lightweight and disciplined: exceptions and overrides are reviewed weekly and turned into threshold, rule, or feature changes; a Decision Review Board meets monthly to approve logic/threshold/model changes, review KPIs and incidents, and authorize autonomy changes; quarterly, the portfolio is tuned, retire or refactor low-value flows, and scale the winners.
The Decision Value Chain
Progress work through the 4D loop from the Decision Intelligence Framework; reuse the same artifacts across phases.
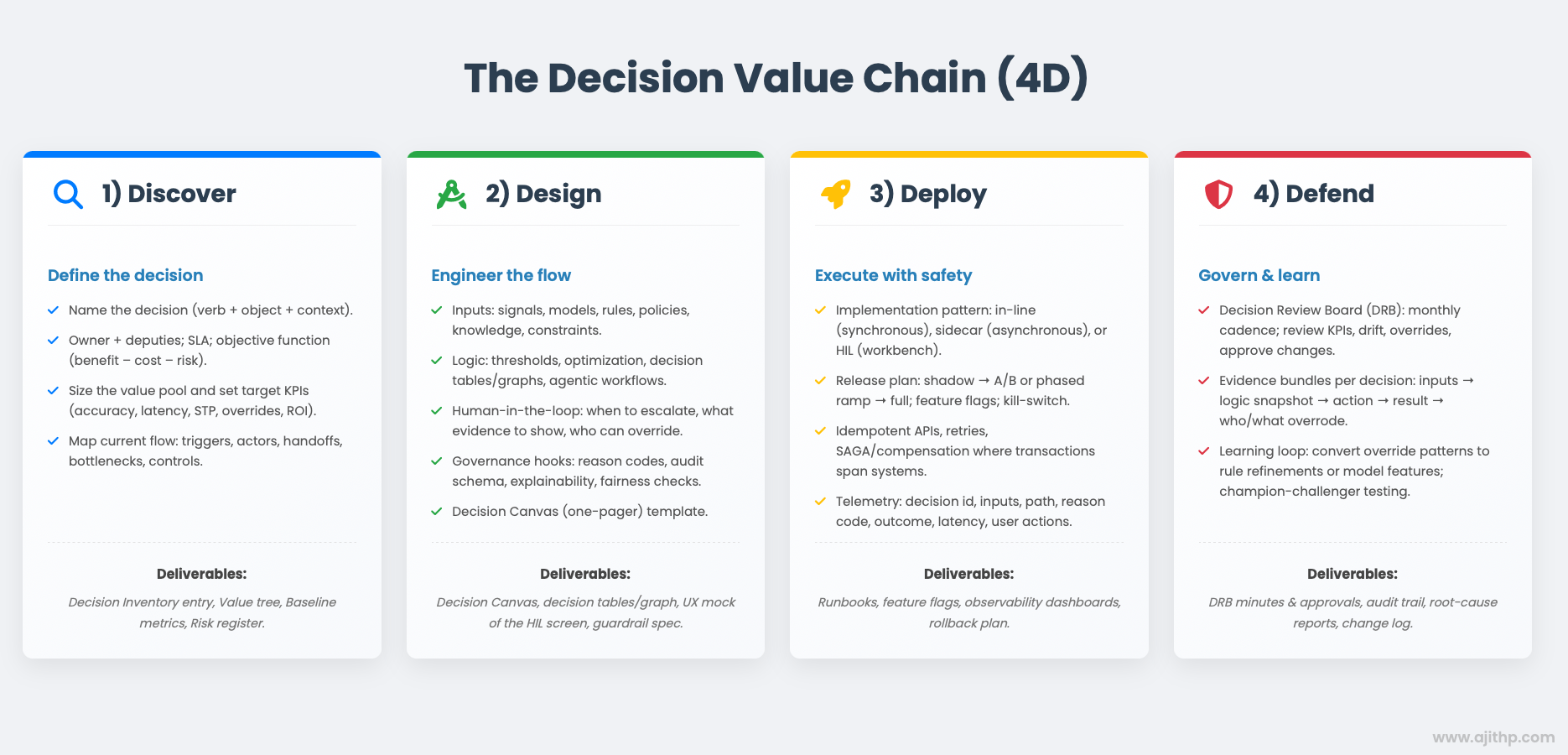
Deployment patterns (how to go live safely)
- Shadow mode: run the decision flow silently; compare against human decisions. Gate to next phase when delta KPIs meet thresholds.
- Champion–Challenger: keep a stable baseline; introduce an alternative with traffic splitting. Promote only on decision-level KPIs.
- Human-in-the-loop first: start with recommendation UIs; move parts of the flow to STP as confidence and guardrails harden.
- Sidecar orchestration: if core systems are brittle, orchestrate decisions in a sidecar service that calls into source/target systems via APIs and emits full evidence.
Governance & Accountability
Governance is the runtime contract for decision-centric AI: who can act, under which policy, with what evidence, and within what SLA. It makes speed safe by enforcing decision rights (STP/HIL/human-led), policy-as-code with precedence and snapshot IDs, and evidence bundles for every action. Kill-switches, rate limits, segregation of duties, and signed change approvals keep boundaries tight, while a Decision Review Board monitors KPIs, drift, and incidents and authorizes autonomy changes. This is how decision velocity scales without regulatory surprises. I have covered governance in detail in the next section

Measure Decision Velocity
Publish Decision Velocity per stream with monthly ROI. Increase autonomy only when speed, accuracy, and resilience are on target; coverage follows, not leads. This keeps trust intact while value compounds. We will dive deeper into Decision Velocity in a later section.
Investment and payback (illustrative)
Plan costs across integration/workflows, decision modeling, features/models, governance, observability & simulation, enablement, and platform capacity.
| Phase | Scope | Typical Investment | Payback Window | Primary Value Drivers |
| Pilot | 1 high-value decision | $250k–$750k | 12–18 mo | 20–35% latency cut; accuracy lift; STP on safe paths |
| Scale (BU) | 3–8 decisions in a BU | $2M–$5M | 24–36 mo | $10–$50M/yr impact at ~$1B revenue; governed automation |
| Enterprise | 15–30 cross-BU decisions | $8M–$20M | 36+ mo | “Decision factory” with shared guardrails & evidence |
| Sustain | Platform & ops run-rate | $1M–$3M/yr | Ongoing | Uptime, controls, change mgmt, DRB cadence |
The figures below are for illustration; actuals vary by organization, systems, and risk posture.
Anti-patterns to avoid
The following anti-patterns can slow decision-making, raise risk, and lead to higher costs from waste.
- Tools-first: buying platforms before selecting the money decision.
- Success theater: counting pilots and model AUC as “impact.”
- No owner: decisions without a P&L-accountable owner and SLA.
- Perma-pilot: endless shadow tests; no gates; no DRB.
- Safety as an afterthought: no evidence bundles, no kill-switch.
- Latency blindness: building great models for decisions that don’t need speed.
Roadmap & gates

Example: filled Decision Canvas (claims triage)
- Decision: Auto-approve, auto-deny, or escalate property-damage claims < $3,000.
- Owner / SLA: Claims Ops Director/decision in < 5 minutes.
- Objective: Minimize loss + leakage at fixed customer effort.
- Inputs: FNOL data, photos, policy limits, fraud score, and historical payouts.
- Logic: Score thresholds + policy rules + photo-AI; deny if fraud > X; approve if score > Y and policy clean; else escalate.
- HIL: Escalate to adjuster with evidence panel; adjuster can override with reason code.
- Controls: Max auto-deny %; rate limits; dual-control for large payouts.
- KPIs: Accuracy, STP %, median latency, override rate, loss ratio, customer CSAT.
- Rollback: Flip to HIL only; revert to last stable thresholds; notify DRB.
Decision factory is a repeatable way to discover, design, deploy, and defend high-value decisions. It aligns investment with measurable outcomes, shortens the time-to-impact, and strengthens governance, allowing you to scale confidently.
Governance & Accountability Framework
Governance is the runtime contract of decision-centric AI. It answers, for every decision: who acted, under which policy, using what evidence, within what SLA, and can we replay it tomorrow? Done well, it is how you scale decision velocity without accumulating regulatory risk.
Decision Rights Matrix (who can do what, when)
Classify decision types by impact and risk; set the default mode, escalation triggers, and caps. Treat this as policy-as-code checked at runtime.

Runtime enforcement: the matrix is evaluated at decision time; if triggers fire, the flow auto-escalates or throttles. All evaluations are logged.
Audit Trails (evidence bundles by default)
Each decision emits an evidence bundle sufficient for internal audit, regulators, and customer redress. It includes a stable decision ID; timestamps; actor (service/user); inputs hash and lineage; model/rule/policy versions; the precise decision path with reason code; SLA/latency; outcome; and, when available, the post-outcome label (e.g., fraud confirmed). Evidence is written to append-only/WORM storage with retention that matches policy; sensitive payloads are minimized and referenced via hashes. A single command can replayany decision by rehydrating the inputs and versions used at the time.
Storage & retention:
- Write-once log (WORM) or append-only store; retention aligned to policy (e.g., 7 years for financial decisions).
- PII minimization: separate sensitive payloads; store references + hashes in the bundle.
Replayability:
- Given decision_id, the platform can replay the exact decision with the same inputs/versions to reproduce the outcome.
Override Capture (learning from human judgment)
Overrides are not exceptions to hide. They are training data for rules, thresholds, and models. Capture why(taxonomy such as error-correction, policy nuance, contextual exception, operational constraint, risk posture change), who (role/approver), and what changed (proposed threshold/rule update), plus supporting evidence. Aggregate weekly; recurring patterns become rules or feature changes with the approval of the Decision Review Board (DRB).
Override taxonomy:
- Error-correction: model/policy wrong
- Policy nuance: rule conflict or outdated policy
- Contextual exception: legitimate edge case
- Operational constraint: system/data unavailable
- Risk posture change: temporary tightening/loosening
Required fields on override:
- Reason code (from taxonomy) + free-text note
- Evidence reviewed (links to docs/screens)
- Approver identity + role; time-to-override
- Impact estimate (benefit/cost)
- Whether new rule/threshold is proposed
Learning loop:
- Aggregate by reason code weekly; convert frequent patterns into rule updates, feature engineering, or threshold adjustments via DRB approval.
Controls Library (make compliance a feature)
Safety is engineered rather than just promised: kill-switches switch flows to HIL, rate limits contain the blast radius, dual control safeguards high-impact actions, and segregation of duties prevents authors from approving their own releases. Testing and simulation, including shadow runs, counterfactuals in a digital twin, and drift/latency chaos, verify fail-safe or fail-open behavior before scaling. Incident response connects alerts to decisions, activates rollbacks or kill switches, and maintains a comprehensive record of events for regulatory purposes.
| Control | Purpose | Where it lives | Runtime behavior |
| Kill-switch | Stop unsafe automation | Platform | Flip to HIL/assist-only; alert owners/DRB |
| Rate limits | Bound blast radius | Policy engine | Token bucket per decision class/actor |
| Dual control | Prevent single-point abuse | Orchestration | Two independent approvals required |
| Bias & impact checks | Fairness + compliance | Pre-deploy & DRB | Gate releases; monitor drift continuously |
| Fallback modes | Maintain service under failure | Orchestration | Fail-open or fail-safe by class; must be explicit |
| Segregation of duties | Reduce conflict of interest | IAM/RBAC | Model authors ≠ approvers; DRB owns final gates |
| Change control | Traceable evolution | GitOps + DRB | PRs for rules/thresholds/models; signed releases |
Decision Review Board (DRB) & Change Governance
The DRB is the control tower for decision change. It ensures every promotion, rollback, or policy shift is safe, auditable, and tied to outcomes. Composition: Decision Owner (P&L), Compliance/Legal, Risk, Data/ML, Ops/SRE, Security. Cadence: monthly as standard, with ad-hoc sessions for incidents.
Scope:
- Approve new/changed decision logic, thresholds, and models.
- Review KPI pack: accuracy, latency, STP, overrides, incidents, drift.
- Validate fairness/impact assessments and bias mitigations.
- Confirm evidence-bundle schema and retention meet policy.
- Approve expansion of autonomy (e.g., move paths from HIL → STP).
Gates:
- Gate 1 (Shadow → Limited): decision KPIs within policy bands; evidence complete.
- Gate 2 (Limited → Scale): stable KPIs; incident rate low; override reasons addressed.
- Gate 3 (Scale → Autonomy increase): post-implementation review passes; guardrails hardened.
Policy Source of Truth (prevent RAG chaos)
Policies live in a single, versioned repository with explicit precedence (Corporate > BU > Local). Each policy has a machine-readable form (YAML/JSON) and a human-readable companion; both are versioned together. A policy engine evaluates precedence at runtime and stamps a policy snapshot ID into every evidence bundle. Change follows a Git-style workflow: policy PR → peer review → DRB approval → signed artifact release.
- Single policy repository: versioned policies with precedence rules (e.g., Corporate > BU > Local).
- Policy-as-code: machine-readable (YAML/JSON) + human-readable docs; both stored and versioned.
- Runtime enforcement: the policy engine resolves conflicts and emits policy snapshot IDs into evidence bundles.
- Change workflow: policy PR → review → DRB approval → signed artifact release.
Testing & Simulation (prove safety before scale)
Safety is established before traffic moves. Establish the following Testing/ simulation before going live.
- Shadow testing: compare automated decisions vs human baseline; analyze deltas.
- Counterfactuals: “What would have happened if…?” using a digital twin.
- Stress & chaos tests: drift, outages, latency spikes; verify fail-safe/open modes.
- Champion–challenger: promote only on decision-level KPIs, not model metrics.
Incident Response (treat decisions like payments)
Run incidents like payments: detect KPI breaches in real time, auto-kill or rollback, link each event to the specific decision with evidence snapshots, and keep an audit-ready remediation log.
- Detect and contain. Freeze promotion and apply caps.
- Notify. Product owner. Risk. Legal. Engineering.
- Roll back to last safe policy snapshot.
- Preserve evidence. Decision ids. Inputs. Outputs. Logs.
- Root cause. Drift. Data quality. Policy error. Model change.
- Replay and test in the twin. Prove safe recovery.
- DRB review. Approve reopen. Track actions to closure.
What auditors/regulators expect
Auditors want proof that decisions are owned, governed, reproducible, and safe at scale. Use this list as your build standard.
- Decision inventory & SLAs: current registry of high-value decisions with owners, objectives, SLAs, and jurisdictions.
- Decision rights & enforcement: documented rights matrix (STP/HIL/human-led) with runtime proof that policies were evaluated and enforced.
- Evidence bundles: replayable records per decision (inputs, lineage, model/rule/policy versions, decision path, reason code, latency, outcome) with versioning.
- Change control: signed logs for rules/models/policies (who changed what, when, why) and promotion gate outcomes.
- Fairness & impact: pre-deploy assessments (by decision and segment) plus continuous monitoring with remediation records.
- Incidents & remediation: full chronology of alerts, actions (kill-switch/rollback), root cause, and DRBsign-off.
- Retention & deletion: policies mapped to each jurisdiction; evidence stored WORM/append-only where required.
This is the minimum for “audit-ready by design.” Encode it once, reuse it across every decision stream.
Governance isn’t a tax on speed, but it’s how you earn the right to scale autonomy. Implementing decision rights, auditable evidence, and override learning creates a system where decisions move fast and stand up to scrutiny.
Technology Shift: From Model Factories to Decision Factories
A major shift is underway in the enterprise AI stack. Historically, machine learning platforms focused on training models. Model factories optimize training throughput, and decision factories enhance decision throughput.
In most organizations, value is lost at the last mile, where smart models clash with fragile workflows, missing guardrails, and no proof. A decision factory shifts the focus by treating the decision as the core artifact and assembling models, rules, policies, and people around it so actions are quick, governed, and repeatable.
Why model factories plateau
Accuracy isn’t action. High AUC still produces shelfware without orchestration into decision paths. Glue code can’t carry audit weight. Cron jobs and ad-hoc bots break under scale and regulatory scrutiny. Governance bolted on late slows you down. And fragmentation means local optimizations without a shared decision inventory or rights matrix.
What a decision factory is (four planes)
Think in planes. Each plane is productized and versioned.
Decision plane. Model the decision-making process, including graphs, tables, thresholds, constraints, and objectives, and encode policy-as-code such as rights, caps, rate limits, and precedence. Use Straight-through processing (STP) for safe slices and human-in-the-loop (HIL) for ambiguous cases. Build simulation and challenger variants in.
Integration & runtime plane. A sidecar decision service orchestrates logic with idempotent APIs, retries, and compensations. Low-latency features feed sub-second calls. Every execution writes a durable decision event under stable schemas.
Trust & governance plane. Each decision emits a replayable evidence bundle (inputs + lineage, model/rule/policy versions, decision path, reason code, latency, outcome). Enforce RBAC/ABAC, segregation of duties, signed releases, fairness/impact gates, and policy precedence. Evidence is WORM/append-only where required.
Observability & cost plane. Telemetry reports speed, accuracy, resilience, coverage, and rolls into Decision Velocity with ROI by stream. Link performance to economics using cost-per-decision (CPD), and hold promotions gates to the rule: CPD ≤ benefit-per-decision for any automated slice.
Promote any automated slice only when CPD is less than or equal to the benefit per decision for two consecutive weeks.

Reference architecture for Decision Factories
Below is a reference architecture for the Decision factories.
- Decision Service (sidecar): the runtime for decision logic, rules, models, and policies.
- Policy Engine: evaluates rights matrix, guardrails, rate limits; stamps policy snapshot IDs.
- Rules/Optimization Engine: decision tables + constraint solver for allocations, pricing, routing.
- Model Inference: online/streaming inference with feature store; shadow and A/B built-in.
- HIL Workbench: operator UI with evidence panel, reason codes, override capture.
- Evidence Store (WORM): immutable decision records; replay and lineage APIs.
- Observability Stack: metrics/logs/traces with decision-aware IDs and dashboards.
- Digital Twin: replay/counterfactuals/stress; required gate before autonomy expansion.
- Connectors & Event Bus: SOR/SAT/CRM/ERP; standardized data contracts.
Interoperability
Adopt a decision event schema with global “decisioned”, reason codes, snapshot IDs, and lineage hashes. Store rules/policies as code and evidence in open formats so any decision can be replayed even outside a vendor stack.
Security, privacy, residency
Design security into the decision artifact. Minimize PII and mask at field level; tokenize sensitive attributes; store raw payloads separately and reference them by hashes in evidence. Use KMS with region-scoped keys, per-tenant isolation, and deny-by-default access. Enforce lawful basis, retention, and deletion at the policy layer so the runtime can prove that a decision complied with residency and purpose restrictions. Evidence exports are scoped, signed, and watermarkable; break-glass access is logged and time-bounded.
Human factors at the console
Operators decide whether the system earns autonomy. The HIL workbench needs compact evidence panels (inputs snapshot, versions, reason code), instant explanations, and a one-click override with a shared taxonomy. Queues should batch similar cases, support keyboard flow, and surface why not STP hints. Measure operator dwell time, override rate by reason, and bypass attempts; treat these as product signals, not operator errors.
Migration plan (Model factory to Decision Factory)
What’s actually migrating (and what isn’t)
You’re migrating the decision flows, not just the models.
- Execution path: from in-app glue/cron/bots → a sidecar Decision Service that orchestrates rules, models, and actions.
- Policies & rules: from PDFs and scattered configs → policy-as-code in one repo, enforced at runtime with precedence.
- Evidence & logs: from brittle app logs → replayable evidence bundles in WORM/append-only storage.
- Human oversight: from ad-hoc emails/Slack → a standardized HIL workbench (explanations, reason codes, override taxonomy).
- Metrics & gating: from model AUC and pilot counts → decision-level KPIs with DRB gates (Shadow → Limited → Scale → Autonomy).
- Data contracts: from implicit JSONs → schema-registry + outbox events with a global
decision_id. - Security/compliance: from app-by-app ACLs → RBAC/ABAC, SoD, signed releases, region-scoped keys baked into the runtime.
- Observability & ROI: from app metrics → decision-aware dashboards tied to Decision Velocity and CPD.
You’re not migrating core systems (ERP/claims/CRM) or retraining everything by default. Models can be re-hosted inside the new flow; historical data backfill is optional unless you need full replay.
Migration blueprint (four moves with acceptance criteria)
- Inventory. List 15–30 high-value decisions; record owners, SLAs, current latency/accuracy, failure modes, and jurisdictions.
Acceptance: one-page Decision Canvas per decision; board-visible top-3 to tackle first. - Sidecar & evidence. Lift orchestration into a Decision Service; standardize the decision event schema; emit evidence bundles by default.
Acceptance: 100% of runs produce replayable evidence; policy snapshot IDs present. - Unify policy & HIL. Encode rights, caps, and precedence; standardize the workbench, reason codes, and override taxonomy.
Acceptance: runtime policy enforcement visible in logs; operator UX live; weekly override review running. - Prove & promote. Run shadow, then limited traffic; advance only on decision-level KPIs (speed, accuracy, resilience). Scale when stable; raise autonomy after guardrails harden and sampling remains in place.
Calibrating SLOs
Set per-class SLOs on p50 and p95 latency, decision accuracy (benefit−cost), resilience under drift/outages, and evidence completeness. Tie error budgets to autonomy. Examples:
- Fraud (real-time): p50 < 250 ms; p99 < 750 ms; ≥95% STP; ≥98% evidence completeness.
- Claims triage (near-real-time): p50 < 5 min; 60–80% STP on low-value paths; <5% unexplained overrides.
- Credit actions (mixed): same-session decision for 90% of cases; dual-control for high-impact moves; 100% replayable.
Build vs. buy (fast heuristics) + vendors
Buy when you need audit-ready evidence and HIL this quarter across multiple BUs. Build when you already run strong orchestration/serving and mainly need a decision layer for domain-specific guardrails or strict residency.
Non-negotiables either way: policy snapshot IDs in every decision; WORM evidence with replay; GitOps promotion of all decision assets; open decision event schema.
Platforms vs. Composable: Decision Intelligence platforms (e.g., Palantir, Aera, Peak AI) bundle modeling, orchestration, governance, and evidence, evaluating governance depth, HIL quality, and digital twin maturity. A composable path pairs your orchestrator with a policy engine, rules/optimization, feature store + serving, observability, and an evidence store. Keep decisions, not models, as the source of truth for assets, gates, and metrics.
Risks and mitigations
Scope sprawl → start with one money decision. Glue-code relapse → enforce the sidecar and schema from day one. Governance drag → DRB (Decision Review Board) gates on decision KPIs, not model metrics; publish Decision Velocity monthly. Operator bypass → invest in the workbench before raising autonomy; make overrides a learning loop. Residency/security gaps → encode residency and data-use policy as code; test exports and key rotation in the twin.
Within 30 days: stand up a sidecar Decision Service, switch on evidence by default, and run shadow on one money decision. Publish its Decision Velocity and SLOs, and route changes through DRB with policy-snapshot stamping. In quarter two, scale traffic, standardize HIL, and add the following three decisions on the same rails.
Decision Velocity: The New Boardroom Metric
Decision velocity measures how quickly and effectively signals are converted into actions, portfolio-wide, not model-by-model. It translates AI from a lab metric to an operating metric that the board can steer.
Executive definition
Decision Velocity Index (DVI):
DVI = (Speed Index × Accuracy Index × Resilience Index) × Coverage
- Speed Index: Actual vs target decision latency (0–1).
- Accuracy Index: Net decision quality (benefit − cost) vs target (0–1).
- Resilience Index: KPI stability under drift/outages/shocks vs SLO (0–1).
- Coverage: Share of eligible volume governed/automated with guardrails (0–1).
Report by decision stream (e.g., Fraud, Claims Triage, Credit Actions), then roll up to an enterprise view.
Board dashboard (per decision stream)
For each stream show: current vs. target Speed, Accuracy, Resilience, and Coverage; supporting Adoption(usage, bypass/override rates), and ROI (net $ impact, payback). Display 6–12 month trendlines and a simple DVI gauge.
| Class | Default Mode | Speed Target | Accuracy Target | Coverage Target | Governance |
| Low-risk, high-volume (e.g., small refunds) | STP | Sub-second → minutes | ≥95% | ≥70% STP | Rate limits, reason codes, evidence bundles |
| Medium-risk (e.g., credit line increases) | HIL (assist + escalate) | Seconds → hours | ≥90% | 30–60% STP | Sampled review, dual control at edges |
| High-impact (e.g., major trades, clinical support) | Human-led with assist |
Board view: show trendlines (last 6–12 months), current vs target, and a DVI gauge for each stream.
How to compute the indices (make it auditable)
- Normalize to targets: Index = min(Actual / Target, 1.0) for “higher-is-better”; invert for latency.
- Weighting: Default equal weights for Speed/Accuracy/Resilience; optionally weight streams by economic value when rolling up.
- Time base: Monthly board pack; weekly for DecisionOps.
- Evidence: Every DVI roll-up links to decision-level evidence bundles (who/what/why).
Example (Fraud stream)
- Speed: target 250 ms (p50); actual 300 ms → Speed Index = 250/300 = 0.83
- Accuracy: target 95%; actual 93% → Accuracy Index = 0.98
- Resilience: target “<10% degradation under shock”; observed 8% → Resilience Index = 1.00
- Coverage: 65% of eligible transactions under governed STP/HIL → Coverage = 0.65
- DVI = 0.83 × 0.98 × 1.00 × 0.65 = 0.53 (on a 0–1 scale).
- Actions: Improve feature freshness to hit 250 ms; lift STP in safe segments to 75%; keep resilience guardrails.
Anti-gaming principles (Goodhart-proofing)
- Decision-level accuracy, not model AUC. Optimize net benefit (include costs of false actions).
- Dual latency metrics: report p50 and p95; median alone hides queuing failures.
- Guardrails before coverage: Raise coverage only when Speed/Accuracy/Resilience meet thresholds.
- Track bypass & override rates: decreasing to zero isn’t a win if it hides operator distrust.
- Independent Finance sign-off on ROI; tie incentives to DVI + ROI, not model count.
Instrumentation (what to log)
For every decision: decision_id, timestamps (arrival/decision/action), inputs hash, model/policy versions, decision path, reason code, outcome, SLA compliance, operator action (if any), post-outcome label (when available). This powers:
- Real-time DVI tiles per stream.
- Root-cause on spikes (latency, overrides, accuracy dips).
- Audit-ready replay of any number the board sees.
Operating cadence
- Weekly DecisionOps: exceptions & overrides, SLA breaches, drift alerts, “why not STP?” review.
- Monthly Board pack: DVI per stream, ROI, incidents, autonomy changes (HIL → STP), top risks and mitigations.
- Quarterly: portfolio rebalancing—retire decisions that don’t move KPIs; double-down on outsized performers.
Decision velocity turns AI into a board metric with teeth. When you measure speed, accuracy, resilience, and coverage, and only promote autonomy as those stabilize, you compound ROI while staying audit-ready. Keywords: decision velocity, AI performance metrics, AI KPIs for executives.
Consequences of Inaction
Failing to shift from model-centric activities to decision-centric execution results in increasing negative consequences. These risks are not abstract, and they will show up as regulatory issues, decreased valuations, and loss of talent.
The three big risks
- Regulatory non-compliance
- What it looks like: No decision owner, no auditable trail (“who decided what, based on which evidence”), inconsistent policies across regions, and inability to replay a decision.
- Exposure: EU AI Act–style obligations (risk management, data governance, transparency, logging, human oversight, post-market monitoring), sector rules in BFSI/healthcare, and internal audit requirements. Courts and regulators hold the enterprise accountable for AI actions, not the vendor or model.
- Impact: Fines and remediation orders, forced rollback to manual processes, product delays, increased capital/reserve requirements, and damaged trust with regulators and customers.
- Investor skepticism
- What it looks like: A parade of pilots, vanity metrics (tokens used, prompts answered), no P&L tie-back, no board-level KPI.
- Exposure: Analysts and boards discount AI claims that lack audited ROI; persistent “pilot purgatory” signals weak governance and poor operating leverage.
- Impact: Lower valuation multiple, higher cost of capital, impairment of capitalized software, and budget constraints that stall genuinely high-value work.
- Talent attrition
- What it looks like: Senior AI/ML engineers and product leaders cannot land work in production; overrides and bypasses are ignored; “success theater” replaces outcomes.
- Exposure: High-performers leave for impact-first organizations; remaining staff resort to shadow tools and unmanaged data flows to get things done.
- Impact: Loss of institutional knowledge, slower delivery, security holes, and rising replacement costs.
Early-warning indicators (treat these as leading signals)
- Rising manual bypass and override rates with no fix loop.
- Time-to-approve policy/model changes is growing each quarter.
- Weekly Active Users of decision tools are falling; operators are building side spreadsheets.
- Increase in audit exceptions around explainability, retention, or access control.
- Pilot count up, production decisions flat; no “money decision” in flight.
Risk-to-mitigation map (board view)
| Risk | Enterprise Exposure | Leading Indicator | Immediate Mitigation |
| Regulatory non-compliance | Fragmented policies, no replayable decisions | Audit findings; unresolved incidents | Stand up a Decision Review Board; enforce policy-as-code and evidence bundles per decision. |
| Investor skepticism | AI impact not tied to P&L or KPIs | “AI updates” with no ROI; capex burn | Publish Decision Velocity and ROI by decision stream in the board pack; freeze net-new pilots until one “money decision” is live. |
| Talent attrition | No path to production; governance theater | Senior IC churn; shadow tools | Create a DecisionOpspathway: shadow → limited rollout → STP, with promotion gates on decision KPIs |
| Operational brittleness | Glue code, no kill-switches | Incident MTTR rising | Add kill-switch/rate-limit controls; simulate fail-open/safe modes in a digital twin |
| Customer trust erosion | Hallucinations, inconsistent outcomes | Complaints/chargebacks | Mandate reason codes and human-in-loop for medium/high-risk classes |
Inaction converts AI from an asset into a liability. Regulatory exposure rises, markets discount your story, and top talent walks. The antidote is a decision-centric operating model, rights, evidence, and velocity, that turns AI into accountable, auditable, compounding value.
The Decision-Centric Enterprise of 2030
By 2030, the industry leaders won’t boast about “models in prod.” Their success will be measured and demonstrated by their Decision Velocity next to ROE and EBITDA. DecisionOps will be a core function, and the Chief Decision Officer (CDO) will own the enterprise decision architecture, portfolio, and promotion gates.
Board snapshot
- DVI per stream (Fraud, Claims, Credit, Pricing, Supply) with targets and deltas in the earnings deck.
- Autonomy with guardrails: low-risk flows are mostly STP; medium/high-risk run HIL with crisp gates.
- Evidence by default: every decision is replayable—inputs, policy/model versions, path, reason code, SLA.
Operating model
- CDO mandate: run Shadow → Limited → Scale → Autonomy; hold owners to SLAs and KPIs.
- DecisionOps squads: cross-functional teams treat each decision as a product (owner, SLA, roadmap).
- Incentives: tie exec and squad compensation to DVI improvement + ROI per stream.
Platform state
- Decision factory: decisions are first-class artifacts (graphs/tables, policies, thresholds) under GitOps.
- Policy-as-code: one source of truth for rights, caps, rate limits, precedence; snapshot IDs stamped in evidence.
- Digital twin + agents: counterfactuals and safety cases before autonomy; agentic workflows escalate inside guardrails.
Assurance
- Zero-surprise audits: evidence bundles and signed change logs satisfy regulators on demand; impact/fairness checks run pre-deploy and continuously.
- Incident playbooks: kill-switches, rate limits, fallbacks; mean time to safe state measured and improved.
Culture
- Decision engineers as a recognized path (product × ops × data × policy).
- Overrides fuel learning: structured reasons update rules, thresholds, and features on cadence; no pilot theater—work starts with a Decision Canvas.
Market signals
- Earnings call: “DVI up 18% YoY; autonomy expanded in two streams; ROI +$32M; zero material findings.”
- Procurement: RFPs require decision artifacts, evidence/replay, policy-as-code, and a digital-twin path, not “LLM compatibility.”
Related Articles
- Model Context Protocol (MCP): The Integration Fabric for Enterprise AI Agents Explores the MCP standard,’ USB-C for AI’, for securely connecting agents to tools and data, essential for scalable decision workflows.
- LLM Observability & Monitoring: Building Safer, Smarter, Scalable GenAI Systems A practitioner’s blueprint for creating trustworthy GenAI applications that endure in production, critical when converting AI signals into decisions.
- AI Code Assistants – Comprehensive Guide for Enterprise Adoption Technical and strategic guidance on adopting AI-assisted development tools, with insights on embedding safety, observability, and adoption in workflows.
- AI-Native Memory and the Rise of Context-Aware AI Agents Discusses memory-enabled agents that build context over time, key for decision systems that need continuity, personalization, and long-term reliability.
- Neuro-Symbolic AI for Multimodal Reasoning shows how hybrid AI models enhance interpretability and reasoning, bridging gaps between perception, logic, and decisions
Conclusion
Enterprises succeed not by accumulating models, but by transforming signals into responsible actions that impact the P&L. The approach is straightforward:
- Start with the decision. Treat each critical decision as a product, with an owner, SLA, KPIs, and a release schedule.
- Implement the DI cycle. Define → Design → Deploy → Defend, ensuring evidence is mandatory and promotion gates are linked to decision KPIs.
- Institutionalize DecisionOps. Create cross-functional teams, a Decision Review Board, and appoint a Chief Decision Officer to manage the enterprise decision framework.
- Track what matters. Display Decision Velocity metrics—speed, accuracy, resilience, coverage—as well as adoption, overrides, and ROI for each decision stream.
- Expand with governance. Use rights matrices, audit trails, override feedback, and a digital twin to turn autonomy from risk into a lasting advantage.
- Execute the 90-day wedge. Make one decisive “money decision,” demonstrate the payback, and then scale using shared components across a portfolio.
- AI is not a technical race. It is a decision race.
References
- CanLII Blog highlight for Moffatt v Air Canada 2024 BCCRT 149
- NIST AI Risk Management Framework 1.0
- NIST AI RMF Playbook
- NIST AI RMF Generative AI Profile
- NIST Trustworthy and Responsible AI Resource Center
- Gartner AI TRiSM glossary
- Gartner press release on AI TRiSM impact
- McKinsey The state of AI in early 2024
- MIT SMR and BCG Expanding AI’s Impact With Organizational Learning 2020
- Self RAG Learning to Retrieve Generate and Critique through Self Reflection
- European Commission AI Act enters into force
- European Commission AI Act overview
- OCC Bulletin 2011 12 Sound Practices for Model Risk Management
- Federal Reserve SR 11 7 Model Risk Management
- OCC Comptroller Handbook Model Risk Management
- Capgemini World Payments Report 2023 press release
Discover more from Ajith Vallath Prabhakar
Subscribe to get the latest posts sent to your email.
You must be logged in to post a comment.