Audio Overview
Liquid Neural Networks (LNNs) emerge at a moment when large‑scale Transformer models dominate AI. Transformers excel in language and vision, yet they press against the Efficient Compute Frontier (ECF): additional parameters give smaller accuracy gains while compute cost, energy use, and data needs rise sharply. These limits affect both training and inference.
Traditional networks also remain largely solid. After training, their weights freeze, preventing real-time learning and degrading performance when input distributions drift. That rigidity is problematic for edge deployments, robotics, and other environments where conditions shift without warning.
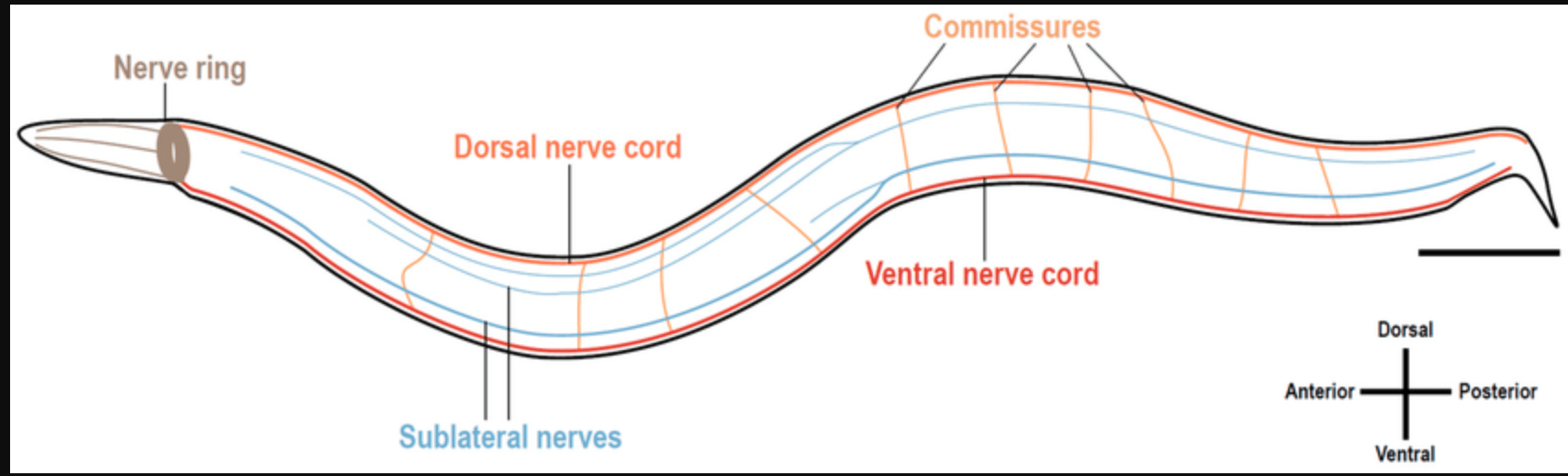
Image Courtesy: Learning the Biochemical Basis of Axonal Guidance: Using Caenorhabditis elegans as a Model
LNNs follow a different path. Each neuron adheres to a differential equation that updates continuously, an idea inspired by the 302-neuron nervous system of C. elegans. The model adjusts its internal parameters as it runs to maintain a fluid and responsive state to new data.
LNNs deliver three core benefits:
- Computational efficiency. An autonomous‑driving lane‑keeping task reaches parity with over 100,000 conventional neurons by using only 19 liquid neurons, reducing power and memory demands and fitting on microcontrollers and mobile SoCs.
- Robustness to drift and noise. Continuous weight updates maintain accuracy when sensors are noisy or environments change, delaying retraining cycles.
- Native handling of time. Continuous‑time dynamics suit irregular time‑series from sensors, financial ticks, and control loops.
Interest in Liquid Neural Networks grows as enterprises confront the scaling limits of current architectures while needing adaptive AI on resource-constrained devices. This article examines LNN mechanics, benchmarks, and a production playbook for technical leaders.
Continuous‑Time Mechanics in Liquid Neural Networks
Liquid Neural Networks derive their adaptability from continuous‑time dynamics, which is different from the fixed-step updates used in most deep‑learning systems.
Discrete Steps vs Continous Flow
Most common neural networks, including standard Recurrent Neural Networks (RNNs) and Transformers, process information in discrete time steps. They handle sequence elements one by one, updating internal states at distinct intervals. Continuous-Time (CT) models describe systems where states evolve smoothly over time (They treat the hidden state as a smooth function of real time). Ordinary Differential Equations (ODEs) define the derivative, the rate at which each variable changes (Rate of change of the system).
Neural Ordinary Differential Equations (NODEs)
Neural Ordinary Differential Equations (NODEs) combine neural networks with continuous-time dynamics. A neural network within a NODE learns to define the rules (the dynamics) governing how the system’s hidden state changes continuously over time. NODEs connect deep learning with dynamical systems theory. They relate closely to Residual Networks (ResNets) and represent a continuous-depth version. This continuous formulation allows handling irregularly timed data and adaptive computation. However, NODEs require numerical ODE solvers to compute state evolution, which can be computationally slow and limit practical application.
Liquid Time‑Constant networks (LTC)
Liquid Time-Constant (LTC) networks are a specific type of LNN based on continuous-time principles. They build upon models where a system’s state decays towards equilibrium at a rate determined by a time constant (τ). This time constant dictates the system’s memory span.
The core LTC innovation is making this time constant input-dependent and dynamic. Each neuron-like unit has an adjustable mechanism, controlled by a small internal neural network (a gate), that modifies its effective time constant based on the current state and input.
This allows the network to adjust its temporal processing dynamically. It can shorten its memory horizon for rapidly changing inputs or lengthen it to capture long-term dependencies. LTCs are designed for stability and offer high expressivity. Like NODEs, they typically use numerical ODE solvers for state computation during training.
Closed-form Continuous‑time models (CFC)
Numerical ODE solvers may slow Liquid Time‑Constant (LTC) networks because they must iterate through many micro‑steps to update each state. Closed‑Form Continuous‑Time (CfC) models remove this overhead. Researchers start with the LTC differential equation, isolate the integral that governs state change, and derive an approximate analytical formula for that term. They then implement this formula as a compact neural layer and add two small stability tweaks: a bounded gating function to keep values in range and a learnable scaling factor to control drift.
Because CfC updates use one direct calculation instead of thousands of solver steps, training and inference run 1–5 orders of magnitude faster. Tests show less than a two‑percent accuracy drop on standard sequence benchmarks, so CfC keeps almost all of the LTC’s expressive power. This speed-to-accuracy balance makes continuous adaptation feasible in edge devices and other real-time systems.
Operational benefits. Continuous‑time updates avoid re‑storing large hidden states at every step. Memory use stays almost constant as sequences lengthen, and latency equals a single closed-form calculation. These properties suit applications such as ECG monitoring, seismic sensing, and network‑packet analysis, where samples arrive at uneven intervals and decisions must occur within milliseconds.
Both LTC and CfC families fall under the Liquid Neural Network umbrella because they share the core feature of continuous internal adaptation. This gives engineers a fast, resource-efficient option for real-time learning tasks that discrete models handle poorly as data rates rise.
Architecture Comparison of Liquid Neural Networks with Other Sequence Models
Liquid Neural Networks (LNNs) differ from Transformers, Hyena, and State‑Space Models (S4, Mamba) in mechanism, speed, accuracy, and formal capability. The key trade-offs appear below.
Architectural Mechanics
- Liquid Neural Networks (LTC / CfC). Continuous‑time recurrence. An input-dependent time constant τcontrols every state update. CfC computes the update in one closed-form step and avoids numerical solvers.
- Liquid‑S4. Embeds linearised LNN dynamics inside an S4 transition matrix and makes that matrix depend on the current input. This blends LNN causality with S4 efficiency.
- Transformers. Parallel self-attention across tokens. Captures long context but needs O(N²) computation and memory for sequence length N.
- Hyena. Long convolutions plus gated modulation. Reaches O(N log N) complexity through Fast Fourier Transforms.
- S4 / Mamba (SSMs). Structured State‑Space Models. A latent state maps inputs to outputs with O(N) or O(N log N) cost; Mamba adds an input-gated scan that improves language tasks.
Benchmark Performance
- Long‑Range Arena. Liquid‑S4 averages 87.32 % across six tasks. Hyena and S4 families match or exceed standard Transformers on most splits.
- Language modelling. Mamba meets or passes Transformers of equal size and generates text about five times faster. Hyena approaches Transformer perplexity on WikiText‑103. Large-scale LNN language results remain limited, though CfC shows solid perplexity on mid-sized sets.
- Vision and audio. Hyena operators replace attention in ViT without accuracy loss on ImageNet‑1k. Liquid‑S4 attains 96.78 % on Speech Commands with 30 % fewer parameters than S4. CfC guides quadrotor flight from raw pixels.
- Time‑series and control. LTC and CfC excel at drone control, stock prediction, and hospital‑stay forecasting; Liquid‑S4 performs well on BIDMC vital‑sign data.
Efficiency and Scalability
| Model | Time & memory growth (sequence length N) | Typical inference notes |
| Transformer | O(N²) | 8 k‑token limit on 24 GB GPU |
| Hyena | O(N log N) | 64 k tokens on one GPU, 100 × faster than optimized attention at that length |
| S4 / Mamba | O(N) or O(N log N) | Streams >300 tokens ms‑¹ on A100; no large context cache |
| LNN (CfC) | O(N) | 19‑unit lane‑keeping model draws <50 mW, trains in minutes |
Training cost follows the same pattern: For example, GPT‑3‑class Transformers need thousands of PF‑days, a 1 B‑parameter Mamba needs tens of PF days, and a 30 k‑parameter CfC controller finishes in under 0.01 PF‑days.
Theoretical State Tracking
- Transformers, S4, Mamba. Fixed-depth versions sit in complexity class TC⁰. They cannot represent functions such as permutation composition that require stronger sequential memory.
- Liquid‑S4. Input-dependent transition matrices move the model to NC¹, allowing finite‑automaton simulation and richer state tracking.
- Liquid Neural Networks. Continuous‑time dynamics give high empirical memory and causal reasoning. A formal class placement is open, but LTC outperforms other Neural‑ODE families in expressivity tests.
TC⁰. This class covers problems that a circuit with only a constant number of layers can solve, no matter how long the input is. Each layer may hold many “threshold” gates that fire when a weighted sum of their inputs crosses a fixed value. Such shallow circuits can do simple tasks like counting the majority of ones in a bit‑string or adding two binary numbers. They cannot keep a detailed step-by-step state because all work happens in only a few stacked operations.
NC¹. Here the circuit depth may grow, but only as fast as the logarithm of the input length, roughly adding one extra layer whenever the input size doubles. This slight increase in depth lets the circuit perform more involved sequential logic, such as composing permutations or simulating a deterministic finite automaton. In parallel‑computing terms, NC1 problems finish in logarithmic time when many processors work at once.
Architecture Comparison Summary (Conceptual)
| Feature | LNN (CfC) | Liquid-S4 | Transformer | Hyena | S4 (Linear SSM) | Mamba (Selective SSM) |
| Core Idea | Adaptive Continuous Flow | Adaptive SSM | Parallel Attention | Smart Long Convolutions | Structured SSM | Input-Aware SSM |
| Scaling (Time) | Efficient (Linear) | Efficient (Near-Linear) | Poor (Quadratic) | Good (Near-Linear) | Good (Near-Linear) | Excellent (Linear) |
| Inference Speed | Fast (Recurrent) | Fast (Recurrent) | Slow (Needs Cache) | Fast (Recurrent) | Fast (Recurrent) | Very Fast (Recurrent) |
| Memory Use (Cache) | Low | Low | High | Low | Low | Low (Selective) |
| Training Parallelism | Limited (Recurrent) | High (Convolutional) | High | High (Convolutional) | High (Convolutional) | High (Parallel Scan) |
| State Tracking Power | Likely Strong (Causal?) | Yes (>TC0) | Limited (TC0) | Likely Limited (?) | Limited (TC0) | Limited (TC0) |
| Adaptability | Very High | High | Low | Moderate | Low | High |
(Note: Scaling is typical. State Tracking refers to the theoretical capability for hard sequential tasks based on)
SSMs and Hyena offer efficient alternatives to Transformers for long sequences. Standard SSMs (S4, Mamba) share theoretical state-tracking limitations with Transformers. Explicit input-dependence in state transitions (Liquid-S4, Mamba ) appears key to enhancing SSM expressivity. LNNs excel in continuous-time adaptation, particularly for control and time-series tasks. Architecture choice depends on application specifics like sequence length, task type, budget, and adaptation needs.
Engineering Guidelines
- Select Transformers when parallel hardware is abundant and sequences stay short.
- Choose Hyena or Mamba for long documents running on a single GPU.
- Deploy Liquid Neural Networks on edge devices or control loops requiring millisecond updates and low power.
- Use Liquid‑S4 when SSM efficiency is required and when state tracking matters are provable.
Edge‑Ready Foundation Models: Benchmarks & Ecosystem

The growing demand for advanced AI capabilities on edge devices—such as smartphones, vehicles, IoT sensors, and embedded systems—drives the exploration of architectures beyond Transformers. Liquid Neural Networks and their derivative, Liquid Foundation Models (LFMs), are particularly well-suited for this edge AI revolution, given their ability to operate within limited computational resources, power, and memory.
LNNs: Designed for the Edge
The core properties of LNNs align naturally with the constraints of edge computing:
- Computational Efficiency: LNNs are designed to achieve high performance with remarkably compact architectures. They require orders of magnitude fewer parameters than traditional deep networks for similar tasks. This efficiency stems from their sparse connectivity (in some variants like NCPs), the expressive power of their adaptive neurons, and the algorithmic efficiency, especially of CfC variants that avoid costly ODE solvers.
- Reduced Resource Consumption: This architectural efficiency translates directly into tangible benefits for edge deployment:
- Lower Latency: Faster processing enables real-time decision-making, which is crucial for applications like autonomous systems and interactive devices.
- Lower Power Consumption: Reduced computational load leads to significant energy savings. This is vital for battery-powered devices and sustainable AI practices, reducing infrastructure costs and CO2 emissions.
- Smaller Memory Footprint: LNNs require less memory for storing parameters and activations, making it feasible to deploy them on devices with limited RAM and storage.
- Offline Capability: Their efficiency allows complex AI tasks to run locally on the device without constant reliance on cloud connectivity. This enhances privacy, reduces communication costs, and enables operation in disconnected environments.
Liquid Foundation Models (LFMs) and STAR Architecture
Liquid AI, a company founded by LNN researchers, has introduced Liquid Foundation Models (LFMs), a series of generative AI models built on LNN principles. LFMs aim to deliver state-of-the-art performance across various scales while embodying the efficiency and adaptability inherent in LNNs.
Key LFM offerings include:
- LFM-1B (1.3B parameters): Designed for highly resource-constrained environments like smartphones and basic embedded systems.
- LFM-3B (3.1B parameters): Optimized specifically for edge deployments that require moderate computational power (e.g., higher-end mobile, edge servers, robots, drones).
- LFM-40B (Mixture of Experts, 12B active parameters): Targets more complex tasks typically handled by larger cloud-based models, but is still designed with efficiency principles.
Liquid AI also introduced the STAR (Scalable Transformer Alternative Representations) architecture. This framework potentially uses techniques like evolutionary algorithms and hierarchical encoding (“architecture genomes”) to automatically discover and optimize AI architectures that balance performance and efficiency. STAR significantly reduces resource demands, such as inference cache size and parameter counts, compared to Transformers and other hybrid models, while maintaining or even exceeding their predictive performance. Techniques like weight sharing and Mixture of Experts (MoE) layers for selective activation contribute to achieving near-constant inference time and memory complexity, even for longer inputs.
LFM Performance and Efficiency Claims
Liquid AI positions LFMs as direct competitors to established LLMs from major players, emphasizing superior efficiency as a key differentiator, particularly relevant for edge scenarios.
Benchmark Performance: LFMs are benchmarked against standard LLM evaluation suites (MMLU, Hellaswag, ARC-C, GSM8K, etc.). Results indicate:
- LFM-1B reportedly sets a new state-of-the-art in the ~1B parameter class, outperforming models like Meta’s Llama 3.2 1.2B, Apple’s OpenELM 1.1B, Microsoft’s Phi 1.5, and Google’s Gemma 2 Base 1.4B on benchmarks like MMLU and ARC-C.
- LFM-3B is positioned as the top model among 3B parameter architectures (Transformers, hybrids, RNNs), outperforming older 7B/13B models and achieving performance comparable to Microsoft’s Phi-3.5-mini (3.8B) while being smaller.
- Memory Efficiency: LFM’s reduced memory footprint is a crucial advantage for edge deployment, particularly when handling long input sequences. Unlike Transformers, whose KV caches grow linearly with sequence length and consume significant memory, LFMs utilize optimized input compression techniques. This allows LFMs to manage longer contexts without a proportional increase in memory usage.
- Context Length: LFMs are trained to maximize recall across their input range. LFM-1B and LFM-3B both support a 32k token context length. LFM-3B achieves an “effective” context length of 32k on the RULER benchmark (score > 85.6), significantly better than competitors like Llama 3.2 3B (effective length 4k) and comparable to larger models like Llama 3.1 8B, enabling long-context tasks on edge devices.
- Inference Efficiency: LFMs claim near-constant inference time and memory complexity; generation speed is not significantly impacted by growing input context length.
- STAR Efficiency: The STAR framework demonstrated significant reductions in cache size (up to 37% vs. hybrid models, 90% vs. Transformers) and parameter count (up to 13%) while maintaining or improving performance on benchmarks.
The following table summarizes performance data for edge-relevant LFMs against key competitors, based on Liquid AI’s reported benchmarks:
LFM Edge Performance Summary
| Model | Params | Target Use Case | MMLU (5s) | GSM8K (5s) | Context (Claimed) | Context (Effective, RULER 32k) | Memory Footprint (vs Transformer) |
|---|---|---|---|---|---|---|---|
| LFM-1B | 1.3B | Resource-Constrained | 58.5 | 55.3 | 32k | N/A | Reduced |
| OpenELM (Apple) | 1.1B | Edge | 52.6 | 40.4 | 2k | N/A | N/A |
| Llama 3.2 (Meta) | 1.2B | Edge | 54.4 | 33.4 | 128k | N/A | Standard |
| Phi 1.5 (Microsoft) | 1.4B | Edge | 64.2 | 31.6 | 2k | N/A | Standard |
| Gemma 2 Base (Google) | 1.4B | Edge | 64.3 | 17.7 | 8k | N/A | Standard |
| LFM-3B | 3.1B | Edge Optimized | 66.16 | 70.28 | 32k | 89.5 | Significantly Reduced |
| Gemma 2 (Google) | 2.6B | General | 56.96 | 44.28 | 8k | N/A | Standard |
| Llama 3.2 (Meta) | 3B | Edge | 59.65 | 79.15 | 128k | 74.1 | Standard |
| Phi-3.5-mini (Microsoft) | 3.8B | Edge | 68.47 | 79.15 | 128k | 87.3 | Standard |
(Note: Benchmark scores sourced from Liquid AI reports.Effective context length based on RULER benchmark score > 85.6. Memory Footprint is qualitative based on claims.)
Edge Benchmarking Landscape and Hardware
While LFMs are benchmarked on standard NLP tasks, specific edge performance metrics like latency, power consumption, and resource utilization are crucial. Research on deploying LNNs directly onto edge hardware provides some insights:
- FPGAs: Studies integrating LNNs with Principal Component Analysis (PCA) for input dimensionality reduction on FPGAs demonstrated superior performance (accuracy, energy efficiency, latency, resource utilization) compared to traditional feed-forward and deep neural networks. Hardware-aware optimizations like quantization and parallel processing were key.
- Neuromorphic Hardware: Implementations on platforms like Intel’s Loihi 2 have shown promise, achieving high accuracy (91.3% on CIFAR-10 related task) and low energy consumption (213 μJ/frame). However, mapping LNNs’ continuous-time dynamics onto discrete neuromorphic hardware presents challenges, requiring careful translation to preserve temporal information and manage complexity.
- General Embedded Systems (MCUs, Raspberry Pi, Jetson): While LNNs’ efficiency makes them conceptually suitable for platforms like Raspberry Pi or generic microcontrollers (MCUs), specific, published benchmarks detailing latency and power consumption on these common platforms were scarce in the provided materials. The Jetson platform was mentioned for evaluating other AI models’ compression and speed, but not specifically for LNNs. Optimized LNN variants like LTC-SE explicitly target resource-constrained embedded systems, thus focusing on flexibility, compatibility, and improved code organization. Liquid AI is actively optimizing LFMs for various hardware platforms, including NVIDIA, AMD, Qualcomm, and Apple silicon.
The current state suggests a gap between the theoretical potential and widespread, standardized edge benchmarking of LNNs. While specialized hardware implementations (FPGA, neuromorphic) show promise, performance data on ubiquitous edge platforms is less available compared to the extensive LLM benchmarks presented for LFMs. This indicates a developing ecosystem where realizing the full edge potential might require further optimization and platform-specific tuning. Variants like LTC-SE and hardware-aware techniques highlight the ongoing effort to bridge this gap. Liquid AI’s strategy of competing on standard LLM benchmarks while emphasizing efficiency aims to establish LFMs as powerful general models that inherently excel at the edge due to their LNN foundations.
Enterprise Playbook: Bringing LNNs into Production

Integrating any novel AI architecture like LNNs into enterprise production environments requires careful consideration of the entire machine learning lifecycle, which includes MLOps, security, and compliance. While LNNs offer unique advantages, they also introduce specific challenges compared to more established models like Transformers.
MLOps and Deployment Considerations
Machine Learning Operations (MLOps) practices aim to streamline the development, deployment, and maintenance of ML models in production. Deploying LNNs involves several considerations:
- Potential Benefits:
- Simplified Artifacts: The smaller size of LNN models could lead to smaller deployment packages and potentially faster deployment times.
- Reduced Infrastructure Costs: Higher computational efficiency might translate to lower requirements for serving hardware (CPU/GPU, memory), reducing operational expenses.
- Potential Challenges:
- Monitoring Dynamic Behavior: The core feature, continuous adaptation poses a significant MLOps challenge. Unlike static models that degrade predictably, LNNs can change their behavior in response to live data. This necessitates robust, potentially near-real-time monitoring systems capable of detecting performance degradation and unexpected behavioral shifts or adaptation to concept drift. Standard monitoring approaches will need augmentation.
- Reproducibility and Debugging: The dynamic internal states governed by differential equations can make it harder to reproduce specific inference outcomes or trace the root cause of errors compared to models with fixed weights and discrete steps. Debugging unexpected behavior might require new techniques or deeper insights into the model’s continuous dynamics.
- Tooling Ecosystem Maturity: The MLOps ecosystem has many tools for managing Transformer-based models. However, specific, mature tools or frameworks offering first-class, out-of-the-box support for the unique aspects of LNN deployment, monitoring (especially adaptive behavior), and debugging appear less prevalent. Integration with existing MLOps pipelines might require custom development or reliance on vendor-specific solutions (e.g., Liquid AI’s Liquid Engine ). NCPs, an LNN variant, were noted as potentially easing model management in MLOps due to robustness to hyperparameter changes.
- Hardware Optimization: Achieving optimal performance, especially on edge devices, may necessitate hardware-specific optimizations like quantization, pruning, or deployment on specialized hardware (FPGAs, neuromorphic chips), adding complexity to the deployment pipeline. Liquid AI’s efforts to optimize LFMs for various hardware platforms aim to address this.
- Scalability: While individual LNN models are small, ensuring the overall system scales to handle enterprise-level throughput and complex workflows requires careful architectural design and infrastructure planning.
The inherent adaptability of LNNs creates a fundamental tension: the very property enabling their unique capabilities complicates traditional MLOps practices built around predictable, static models. Productionizing LNNs effectively requires embracing this dynamism and developing monitoring and management strategies that can handle continuous evolution.
Security Considerations
The unique characteristics of LNNs also introduce specific security considerations:
- Adversarial Vulnerabilities: LNNs, like other neural networks, are susceptible to adversarial attacks, inputs crafted to cause misclassification or incorrect behavior. The dynamic nature of LNNs presents potential challenges and unique attack vectors:
- Evolving Attack Surface: Continuous parameter updates might expose transient vulnerabilities that attackers could exploit.
- Defense Challenges: Traditional defenses like adversarial retraining (training the model on adversarial examples) assume a static model and may be less effective or harder to apply to continuously adapting LNNs.
- Data Poisoning: LNNs’ ability to learn continuously from incoming data makes them particularly vulnerable to data poisoning attacks that occur after initial deployment. Malicious actors could potentially inject crafted data points over time to corrupt the model’s behavior or introduce biases. This differs from traditional models, where poisoning primarily targets the initial training dataset. This necessitates robust and continuous input validation mechanisms. The challenge of models degrading over time due to evolving threats (adversarial drift) is particularly relevant in domains like malware detection.
- Mitigation Strategies: Addressing LNN security requires tailored approaches:
- Hybrid Architectures: Combining static neural network components (for critical, stable functions) with adaptive LNN modules might reduce the attack surface.
- Input Validation: It is crucial to implement rigorous, continuous validation and anomaly detection on incoming data streams before they are processed or used for adaptation.
- Parameter Constraints: Selectively freezing critical parameters or imposing bounds on adaptation could prevent malicious manipulation of core functionalities.
- Robust Auditing: Detailed logging of parameter changes and internal state dynamics can help detect suspicious activity.
- Formal Methods: Concepts like formal verification and cryptographic immutability, proposed in broader AI safety frameworks like “Ethical Firewalls,” could potentially be adapted to certify LNN behavior.
- Isolation Techniques: For LLM-like applications, patterns like the Dual LLM approach (isolating privileged components from untrusted input) might be relevant.
Security for LNNs cannot be an afterthought; it must account for their dynamic nature from the design phase through deployment and ongoing operation.
Compliance and Explainability
In many enterprise contexts, particularly regulated industries like finance and healthcare, AI models must comply with regulations (e.g., GDPR, HIPAA) and provide a degree of transparency or explainability regarding their decisions.
- Interpretability Potential: LNNs are often touted as being more interpretable than large, opaque “black box” models like massive Transformers. This potential stems from:
- Smaller Size: Fewer neurons and parameters can make the network’s structure easier to analyze.
- Structured Design: Some LNN variants, like CfCs with sparse or low-rank connectivity, incorporate interpretable priors. Neural Circuit Policies (NCPs), built using LTC/CfC components, are also associated with interpretability and auditability.
- Extractable Logic: It might be possible to extract decision trees or analyze firing patterns in smaller LNNs to understand decision pathways.
- Interpretability Challenges: Despite the potential, the continuous and dynamic nature of LNNs can still pose challenges for explainability. Tracing the exact influence of past inputs on a current decision through evolving differential equations can be complex. Distinguishing between normal adaptation and anomalous or compromised behavior solely based on output might be difficult. Therefore, while potentially more interpretable than giant Transformers, achieving practical, reliable explainability for complex LNNs likely requires dedicated techniques and architectural choices (e.g., sparsity, modularity).
- Regulatory Compliance: The potential for enhanced interpretability makes LNNs attractive for regulated sectors. Regulations like GDPR often include considerations around automated decision-making and the need for explanations. In healthcare, understanding diagnostic or prognostic models is crucial for clinical acceptance and safety. LNNs’ transparency could facilitate compliance and build trust. Additionally, techniques like Federated Learning, which can be used with LNNs (demonstrated with NCPs ), can help address data privacy concerns central to regulations like HIPAA and GDPR by keeping raw data decentralized. While direct mentions of LNNs achieving specific GDPR or HIPAA certification are absent in the provided materials, their architectural properties align well with the principles of transparency and efficiency often required.
Enterprises considering LNNs must weigh the potential benefits of adaptability and efficiency against the current maturity of the ecosystem and the unique challenges in MLOps, security, and achieving practical interpretability. Early adoption may require significant internal expertise or close collaboration with specialized vendors like Liquid AI, particularly for deploying and managing these dynamic systems in mission-critical applications.
Case Studies
Examining specific applications provides concrete evidence of LNN capabilities and performance in various domains.
Robotics
Robotics, particularly tasks involving interaction with dynamic and unpredictable environments, represents a prime application area for LNNs due to their adaptability and efficiency.

- Autonomous Navigation: This is arguably the most well-documented success story for LNNs. Researchers at MIT CSAIL developed an imitation learning framework using LNNs (specifically, CfCs implemented with Neural Circuit Policies wiring) to train drones for vision-based fly-to-target tasks.
- Key Findings: Compared to state-of-the-art recurrent architectures like LSTMs and ODE-RNNs, the LNN-based agents demonstrated significantly superior robustness and generalization to unseen environments (Out-of-Distribution or OOD performance). Drones trained in one environment (e.g., a forest in summer) could successfully navigate and find targets in drastically different environments (e.g., the same forest in winter, urban landscapes) without retraining. LNN agents learned to distill the core task (fly to the target) from visual inputs and ignore irrelevant environmental features, enabling transferability. CfC-based agents showed remarkable range generalization, successfully navigating from starting points two or three times further than the training data, where LSTMs failed completely. They also exhibited greater resilience to input perturbations (noise, lighting changes) and better handling of target variations (rotation, occlusion). Furthermore, LNNs enabled drones to effectively track moving targets and execute complex multi-step navigation tasks in novel environments.
- Efficiency: These navigation tasks were often achieved using compact LNNs.
- Other Vehicles: LNNs have also been applied successfully in simulations for autonomous ground vehicles, performing tasks like lane-keeping with high efficiency (e.g., using only 19 neurons compared to potentially 100,000 in traditional networks).
Robotic Manipulation: While less detailed in the provided sources than navigation, LNNs are proposed for tasks requiring precision and dynamic adaptation, such as assembly line operations or robotic surgery. Their ability to process real-time sensor feedback makes them suitable for adjusting movements dynamically. One study mentioned developing an LNN (LTC-SE) based control system for a multi-joint cyber-physical arm.
Human-Robot Interaction: LNNs’ potential for interpreting natural language commands in real-time is suggested as a way to make interactions more intuitive.
Multi-Robot Systems: Extending LNN capabilities to coordinate teams of robots is an active research direction , with potential applications in areas like task offloading and scheduling with anomaly detection.
The strong performance in drone navigation, particularly the OOD generalization, provides compelling evidence for LNNs’ ability to learn robust control policies from sensor data in complex, changing environments – a critical capability for autonomous systems.
Finance
The financial sector, characterized by noisy, non-stationary time-series data, is another promising area for LNNs.

- Time-Series Forecasting: LNNs, particularly LTCs, have been applied to predict stock market prices. One study specifically targeted NSE stock prices (Adani Ports, Reliance, Tata Steel), comparing LTC-based architectures against standard RNNs, GRUs, LSTMs, and their bidirectional variants. The hypothesis was that LTCs’ adaptability to rapid fluctuations makes them better suited for the unpredictable nature of financial signals compared to models like LSTMs. While specific quantitative results require consulting the full paper, the study aimed to demonstrate the computational efficiency and accuracy trade-offs. Other work proposed an Uncertainty-Aware LNN (UA-LNN) to explicitly model prediction uncertainty and improve robustness to noise, showing superior performance over standard LNN, LSTM, and MLP models on forecasting tasks based on metrics like R2, RMSE, and MAE. LNNs are generally considered well-suited for financial forecasting due to their ability to process time-series data effectively. Their potential for cryptocurrency price prediction is also noted.
- Anomaly Detection: LNNs’ ability to learn normal patterns and adapt to evolving data streams makes them suitable for detecting anomalies in financial markets. Related applications include intrusion detection systems (IDS) in cybersecurity, where LNNs used within a federated learning framework achieved high accuracy (98.63%), precision (98.60%), and recall (97.88%) on standard IDS datasets (NSL KDD, CSE-CIC-IDS2018), performing on par with LSTM and GRU. LNNs have also been proposed for anomaly detection in 6G network task offloading scenarios. The general problem of time-series anomaly detection is relevant across finance, healthcare, and predictive maintenance.
While promising, the validation depth for financial applications in the provided snippets appears less extensive than for robotics. However, the inherent match between LNN capabilities (time-series processing, adaptation, noise resilience) and financial data characteristics suggests significant potential.
Healthcare
Healthcare presents numerous opportunities for LNNs, particularly in analyzing complex, time-varying patient data from Electronic Health Records (EHRs) and biosignals.

- Medical Time Series / EHR / Biosignals:
- Length of Stay (LOS) Prediction: A notable case study is the StayLTC framework. This multimodal deep learning system uses LTC networks to predict the remaining hospital LOS daily for patients admitted to the ICU. It integrates structured EHR data (captured via Severity of Illness scores like APACHE-II, SAPS-II, SOFA, OASIS) with unstructured clinical notes (processed using BioNER, UMLS standardization, and autoencoders to create dense health vectors) from the large, real-world MIMIC-III dataset.
- Key Findings: StayLTC (LTC using autoencoded notes + SOI scores) achieved strong performance (R2=0.78, MAE=0.20, RMSE=0.24), significantly outperforming baseline models like LSTM and the Transformer-based Informer. Critically, it achieved performance comparable to a sophisticated time-series Large Language Model (TIME-LLM based on Llama2-7B, which had the best accuracy with R2=0.87) but with vastly superior efficiency. StayLTC required only 100K parameters and 1.2 MB of memory, trainable on a CPU in about an hour, whereas TIME-LLM needed 7 billion parameters, 28 GB of GPU memory, and ~3 hours of GPU training time. This highlights LNNs’ potential for delivering high performance on complex healthcare tasks in a resource-efficient manner.
- Other Potential Applications: LNNs are suggested for broader healthcare diagnostics. Their ability to handle time series makes them suitable for processing various biosignals like fMRI or vital signs from datasets like BIDMC (where Liquid-S4 achieved SOTA ). UA-LNN showed strong performance on challenging classification tasks like arrhythmia detection and cancer classification, especially under noisy conditions. Predicting blood glucose levels is another potential application area. While general medical imaging applications are numerous , specific LNN applications in imaging were less detailed in the source material, though GLNN was applied to Optical Coherence Tomography (OCT) image analysis with high accuracy.
The StayLTC study provides a compelling case for LNNs in healthcare analytics, demonstrating their ability to effectively integrate multimodal time-series data and achieve competitive accuracy with significantly lower computational overhead compared to state-of-the-art large models.
Summary of Case Study Insights
From the above use cases, we can see the emergence of a consistent pattern across these domains. LNNs demonstrate their strengths most clearly when dealing with dynamic, noisy, continuous time-series data, where adaptability, robustness, and efficiency are crucial. The quantitative successes in drone navigation (OOD generalization) and healthcare LOS prediction (accuracy vs. efficiency) provide strong validation. While finance applications show promise, the depth of comparative evidence presented in the snippets is somewhat less. A recurring theme is the remarkable efficiency of LNNs, i.e, achieving strong results with significantly fewer parameters and computational resources compared to alternatives, particularly large Transformer/LLM approaches. This reinforces their value proposition for edge computing and resource-constrained environments.
Challenges & Open Research Questions
Despite their promise and demonstrated successes, LNNs are still an emerging technology, and several challenges and open research questions remain.
Training Complexity and Stability
- Computational Cost: The original LTC formulation relies on numerical ODE solvers to compute the forward pass. These solvers can be computationally expensive and slow, making training more complex and resource-intensive compared to standard discrete-time RNNs, especially as model or data complexity increases. The stiffness of the underlying ODEs may also require sophisticated adaptive-step solvers. CfC models were developed specifically to address this bottleneck by providing a closed-form approximation.
- Gradient Issues: As with deep or recurrent networks, LNNs can potentially suffer from vanishing or exploding gradients during training, particularly when modeling long-term dependencies. The continuous dynamics might exacerbate these issues. Architectural modifications in CfCs (like using sigmoidal gating instead of pure exponentials) and techniques like mixed memory architectures aim to improve gradient flow and stability.
Scalability
- Scaling Limits: While individual LNNs are often small, scaling them to handle extremely large datasets or building very deep LNN architectures might face computational challenges compared to highly parallelizable architectures like Transformers. The sequential nature of ODE solving (for LTCs) or recurrent computation (for CfCs) can limit parallelization across the time/sequence dimension during training, although CfCs are significantly faster than LTCs.
- Hardware Acceleration: Efficiently deploying LNNs, especially on edge devices, often requires specialized hardware (FPGAs, neuromorphic chips) or hardware-aware optimizations. Mapping the continuous-time dynamics or complex gating mechanisms of LNNs onto discrete hardware architectures presents unique challenges. Ensuring compatibility and preserving dynamics while optimizing for constrained memory and processing power is an active area.
Robustness and Generalization
- Guarantees vs. Potential: LNNs have shown remarkable robustness in specific cases (e.g., drone navigation OOD), but it is not an automatic guarantee. Their high flexibility can potentially lead to overfitting on training data. Performance can still degrade in dynamic environments if the model or training process is not carefully designed.
- Concept Drift: LNNs’ adaptability offers a potential advantage in handling concept drift without immediate retraining. However, this adaptive learning needs to be compared rigorously against incremental learning strategies, which require new data but might offer more controlled updates. The period of uncertainty before incremental learning models can be retrained highlights a window where adaptive models like LNNs could provide significant utility.
- Noise Resilience: Standard LNNs may produce overly confident predictions in noisy environments due to a lack of inherent uncertainty mechanisms. Research into variants like Uncertainty-Aware LNNs (UA-LNN) aims to address this by enhancing stochasticity.
Theoretical Understanding
- Expressivity Limits: While LTCs are claimed to have superior expressivity within the NODE family , a precise characterization of their theoretical limits, especially compared to other modern architectures like Transformers or SSMs across different task types, is still developing. What computational power is gained or lost by the CfC approximation?. How do they compare in formal complexity hierarchies (e.g., TC0, NC1) relevant for tasks like state tracking?.
- Causality: LNNs are often described as learning causal representations. A deeper theoretical understanding and validation of this claim across different domains would be valuable.
- Uncertainty: Developing principled and computationally efficient methods for quantifying prediction uncertainty within the LNN framework remains an important research direction.
Broader Applicability and Ecosystem
- Task Generality: LNNs have traditionally excelled in sequential, time-series tasks. Extending their effectiveness to non-sequential domains (like static image classification or tabular data) or complex multimodal tasks requires further research and potentially new architectural variants like the proposed Generalized LNN (GLNN).
- Benchmarking: Consistent and wide-ranging benchmarking of LNNs against state-of-the-art models across diverse standard datasets (like LRA, GLUE, SuperGLUE, ImageNet, etc.) is needed to establish their comparative performance more broadly.
- Tooling and MLOps: As discussed previously, the ecosystem of libraries, frameworks, and MLOps tools specifically tailored for LNNs is less mature than for architectures like Transformers, potentially hindering wider enterprise adoption. Optimized variants like LTC-SE aim to improve compatibility with standard frameworks like Keras/TensorFlow.
Key Open Research Questions
Based on these challenges, several key research questions emerge:
- How can LNN training be more stable, efficient, and scalable, particularly for large datasets and deep architectures?
- What are the fundamental theoretical limits of LNN expressivity, especially concerning complex reasoning and state tracking compared to Transformers and SSMs?
- How can the inherent robustness and adaptability of LNNs be rigorously characterized and guaranteed across diverse tasks and under various noise or adversarial conditions?
- What are the most effective and computationally tractable methods for incorporating uncertainty quantification into LNN predictions?
- What are the best practices and architectural modifications needed to effectively apply LNN principles to non-sequential and multimodal data?
- How can the MLOps lifecycle (deployment, monitoring, debugging) be best adapted to handle the continuously evolving nature of LNNs in production?
- What standardized benchmarks and evaluation protocols are needed to fairly assess LNN performance, particularly on edge hardware considering latency and power?
Addressing these questions will be crucial for realizing the full potential of LNNs and transitioning them from a promising research direction to a widely adopted class of AI models. The numerous LNN variants emerging (CfC, Liquid-S4, LTC-SE, UA-LNN, GLNN) suggest that LNNs might be best viewed as a flexible framework whose core principles can be adapted and specialized to overcome specific limitations and target diverse application requirements.
Strategic Takeaways for CTOs & Product Leaders
Chief Technology Officers (CTOs), Product Leaders, and technical executives should strategically evaluate Liquid Neural Networks (LNNs) and Liquid Foundation Models (LFMs). These models represent a shift in AI philosophy by emphasizing dynamic adaptation and efficiency rather than merely serving just as a novel architecture.
1. LNNs Offer a Compelling Alternative Paradigm: Recognize that LNNs are not merely incremental improvements but a fundamentally different approach compared to the dominant scale-centric Transformer paradigm. Their core design principles focus on continuous learning and computational efficiency. This makes them a potential solution for applications where traditional large models falter due to cost, latency, power constraints, or the need to adapt to rapidly changing real-world data streams.
2. Prioritize LNNs for Specific High-Potential Domains: LNNs have demonstrated clear advantages in domains characterized by continuous, dynamic, and often noisy time-series data. Strategic focus should be placed on evaluating LNNs for applications in:
- Robotics and Autonomous Systems: Especially for navigation, control, and perception in unpredictable environments.
- Time-Series Analysis: Including financial forecasting, anomaly detection, and healthcare data analysis (e.g., EHR, biosignals).
- Edge AI: Any application requiring significant AI capabilities on resource-constrained devices.
3. Leverage Efficiency as a Key Business Driver: The potential for dramatic reductions in parameter count, memory footprint, and power consumption is a major strategic advantage of LNNs. This efficiency can translate directly into:
- Lower operational costs (compute infrastructure, energy).
- Feasibility of deploying advanced AI on low-cost edge hardware.
- Meeting sustainability and green computing goals.
- Improved user experience through lower latency in real-time applications.
4. Understand the Architectural Variants and Trade-offs: The term “LNN” encompasses a family of models (LTC, CfC, Liquid-S4, LFMs). Understand the nuances:
- CfCs offer a practical starting point, balancing performance with significant speed advantages over ODE-based LTCs, making them suitable for many real-world deployments.
- Liquid-S4 integrates LNN ideas with SSMs, targeting strong performance on long-sequence benchmarks.
- LFMs (from Liquid AI) provide pre-trained, general-purpose models at different scales, potentially lowering the barrier to entry for generative AI tasks. The choice of architecture should align with specific project requirements regarding performance needs, computational budget, and sequence length.
5. Acknowledge and Plan for Ecosystem and MLOps Gaps: The tooling and established best practices for deploying, monitoring, and managing LNNs in production are less mature than those for Transformers. Be prepared for:
- Potentially higher initial development and integration effort.
- The need for specialized expertise or reliance on vendors like Liquid AI.
- Developing custom solutions for monitoring adaptive behavior and ensuring reproducibility. Factor this into project timelines and resource allocation.
6. Adapt Security and Monitoring Strategies: The dynamic nature of LNNs requires a shift in security and monitoring paradigms. Static defenses and periodic checks may be insufficient. Plan for continuous input validation, real-time anomaly detection in model behavior, and robust auditing mechanisms to address vulnerabilities like ongoing data poisoning and evolving adversarial attacks.
7. Capitalize on Potential Interpretability Gains: In regulated industries or applications where trust and transparency are paramount, LNNs’ potential for greater interpretability compared to massive black-box models can be a significant advantage. However, realizing this benefit may require specific architectural choices (e.g., sparsity) and dedicated analysis efforts.
8. Recommendation: Initiate Targeted Exploration and PoCs: For organizations grappling with the limitations of large static models or seeking to enable sophisticated AI in dynamic or edge environments, now is an opportune time to begin exploring LNNs.
- Initiate Proof-of-Concept (PoC) projects focused on well-matched use cases (e.g., time-series forecasting on internal data, simple control tasks, edge sensor analysis).
- Consider starting with CfC implementations due to their balance of performance and efficiency, or evaluate LFMs from vendors like Liquid AI for generative tasks.
- Build internal expertise or partner with specialists to navigate the unique aspects of LNN development and deployment.
Adopting LNNs represents more than a simple technology upgrade; it’s a potential strategic investment in a different future for AI, one potentially characterized by greater efficiency, adaptability, and closer integration with the dynamic physical world. This requires technical evaluation and a willingness to adapt development and operational processes to accommodate continuously learning systems. The emergence of commercial entities like Liquid AI providing LFMs may significantly accelerate this transition by offering more accessible pathways for enterprise adoption beyond pure research implementations.
Resources & Further Reading
This section provides pointers to key papers, code repositories, and related concepts for deeper exploration of Liquid Neural Networks and associated architectures.
Key Foundational LNN Papers:
- Liquid Time-Constant Networks (LTCs):
- Hasani, R., Lechner, M., Amini, A., Rus, D., & Grosu, R. (2021). Liquid Time-constant Networks. Proceedings of the AAAI Conference on Artificial Intelligence, 35(9), 7657-7666. (Also available as arXiv:2006.04439)
- Closed-form Continuous-time (CfC) Models:
- Hasani, R., Lechner, M., Amini, A., Liebenwein, L., Ray, A., Tschaikowski, M., Teschl, G., & Rus, D. (2022). Closed-form continuous-time neural networks. Nature Machine Intelligence, 4(11), 992–1003. (Preprint arXiv:2106.13898)
- Liquid Structural State-Space Models (Liquid-S4):
- Hasani, R., Lechner, M., Wang, T., Chahine, M., Amini, A., & Rus, D. (2023). Liquid Structural State-Space Models. ICLR 2023 Workshop on Physics for Machine Learning. (arXiv:2209.12951)
- Neural Circuit Policies (NCPs – often use LTC/CfC):
- Lechner, M., Hasani, R., Amini, A., Hutter, F., Rus, D., & Grosu, R. (2020). Neural circuit policies enabling auditable autonomy. Nature Machine Intelligence, 2(10), 642–652.
Key Application Papers:
- Drone Navigation:
- Chahine, M.*, Hasani, R.*, Lechner, M.*, et al. (2023). Robust flight navigation out of distribution with liquid neural networks. Science Robotics, 8(77), eadc8892. (*Equal contribution)
- Healthcare (LOS Prediction):
- Jana, S., Sinha, M., & Dasgupta, T. (2025). StayLTC: A Cost-Effective Multimodal Framework for Hospital Length of Stay Forecasting. arXiv preprint arXiv:2504.05691.
Code Repositories:
- Official Implementations (MIT CSAIL):
- CfC (TensorFlow/PyTorch): https://github.com/raminmh/CfC
- LTC (Original): https://github.com/raminmh/liquid_time_constant_networks
- Liquid-S4: https://github.com/raminmh/liquid-s4
- NCPs (Includes LTC/CfC examples): Likely https://github.com/mlech26l/keras-ncp (Referenced via )
- Community Implementations (Examples):
- LiqudNet (PyTorch): https://github.com/kyegomez/LiqudNet
- lnnrs (Rust WIP): https://github.com/postrv/lnnrs
Companies & Frameworks:
- Liquid AI: Commercial entity developing LFMs based on LNN principles. https://www.liquid.ai/
Read More
- AI Hardware Innovations: GPUs, TPUs, and Emerging Neuromorphic and Photonic Chips Driving Machine Learning This article explores the latest advancements in AI hardware, including neuromorphic and photonic chips, which are pivotal for deploying LNNs effectively. It provides a comprehensive overview of how these hardware innovations support efficient machine learning computations.
- Test Time Compute (TTC): Enhancing Real-Time AI Inference and Adaptive Reasoning Diving into methodologies that optimize AI inference during deployment, this piece discusses Test Time Compute strategies. It aligns with LNNs’ goals of achieving real-time adaptability and efficient reasoning in dynamic environments.
- Benchmarking Large Language Models: A Comprehensive Evaluation Guide While focusing on large language models, this guide offers valuable insights into benchmarking practices. Understanding these evaluation techniques can inform assessments of LNN performance and scalability.
- Unlocking Explainable AI: Key Importance, Top Techniques, and Real-World Applications This article emphasizes the significance of explainability in AI models. It presents techniques and applications that enhance transparency, which is crucial for interpreting the decision-making processes of complex models like LNNs.
- Neuromorphic Computing: How Brain-Inspired Technology is Transforming AI and Industries Exploring the realm of neuromorphic computing, this piece discusses brain-inspired technologies that parallel the continuous-time dynamics of LNNs. It provides context on how such innovations are revolutionizing AI applications across various sectors.
Conclusion
As AI systems scale and diversify, the limitations of conventional architectures—particularly around efficiency, adaptability, and deployment overhead—are becoming increasingly apparent. Liquid Neural Networks (LNNs) address these concerns through a fundamentally different approach: dynamic, continuous-time modeling. Their core strength lies in their ability to update internal states in real-time, enabling adaptation to shifting data distributions without explicit retraining.
Throughout the article, we have examined how LNNs, particularly in their CfC and LTC formulations, outperform traditional models like LSTMs and Transformers in specific domains—autonomous drone navigation, healthcare time-series analysis, and financial forecasting—while using far fewer parameters and significantly less power. These outcomes are not theoretical projections but demonstrated advantages in tasks such as out-of-distribution generalization, low-latency inference, and resilience to noisy or sparse inputs.
However, practical adoption requires addressing several operational realities. Training stability, MLOps compatibility, and explainability remain areas requiring deliberate architectural choices and ecosystem support. The lack of mature tooling for monitoring and debugging adaptive behavior underscores the need for investment in infrastructure, especially for enterprise-scale deployments. Security, particularly in the context of continuous learning and potential for data poisoning, must also be managed differently than with static models.
Despite these challenges, LNNs offer measurable value in scenarios where traditional models struggle: edge computing, variable time-series input, and mission-critical control systems. Their ability to learn causal relationships, maintain temporal coherence, and generalize under constrained supervision positions them as a practical complement—not a replacement—to today’s dominant AI architectures.
The current ecosystem around LNNs is still evolving, but the direction is clear. For organizations seeking efficient, robust, and adaptive AI under tight operational constraints, Liquid Neural Networks represent a viable and forward-compatible option worth evaluating as part of a balanced model portfolio.
Discover more from Ajith Vallath Prabhakar
Subscribe to get the latest posts sent to your email.
You must be logged in to post a comment.