Audio Overview
The Evolution of AI Reasoning
Large Language Models (LLMs) have revolutionized AI capabilities through their remarkable reasoning abilities. Chain-of-thought (CoT) prompting has played a key role in this rapid advancement which, enabled LLMs to tackle complex reasoning tasks with step-by-step articulation. This technique has led to breakthroughs in mathematical reasoning, common-sense understanding, and symbolic problem-solving.
However, this enhanced reasoning capability comes at a significant cost. The verbose nature of CoT prompting results in substantial computational overhead, increased latency, and higher operational expenses. LLMs generate lengthy explanations with each reasoning step, so they consume more tokens. This leads to slower response times and elevated inference costs, which are particularly problematic for real-time applications and high-volume deployments. These challenges create barriers for industries that require fast, cost-effective, AI-powered decision-making.
Introducing Chain of Draft (CoD) Prompting
This is where Chain of Draft (CoD) prompting comes into play. Introduced by researchers from Zoom Communications in their February 2025 paper, CoD represents a significant shift in how LLMs generate reasoning outputs. Unlike traditional CoT methods that produce verbose human-like explanations, CoD draws inspiration from the way humans naturally solve problems—utilizing concise notes, shorthand, and minimal drafts that capture only the essential insights needed to progress toward a solution.
The brilliance of Chain of Draft Prompting lies in its simplicity and effectiveness. By instructing models to generate minimal yet informative intermediate reasoning outputs, CoD matches or surpasses CoT in accuracy while using as little as 7.6% of the tokens. This remarkable efficiency translates into:
- Dramatically reduced latency—making real-time AI applications more feasible.
- Significantly lower computational costs—reducing token usage and inference expenses.
- Comparable or even improved accuracy—demonstrating that verbosity is not essential for high-quality reasoning.
- No fine-tuning or architectural changes are required—CoD is a purely prompting-based strategy that works with existing LLMs.
The researchers demonstrated these advantages across a diverse range of reasoning tasks, providing compelling evidence that effective reasoning does not require excessive verbosity. Their findings suggest that CoD could be a game-changer for deploying sophisticated AI reasoning capabilities in cost-sensitive and latency-critical environments. By significantly reducing computational overhead, CoD ensures that businesses, developers, and enterprises can implement LLM reasoning at scale without prohibitively high costs or performance delays.
Background on Chain-of-Thought (CoT) Prompting
Chain-of-thought (CoT) prompting, introduced in 2022 by Wei et al., emerged as a groundbreaking technique that significantly improved LLMs’ ability to tackle multi-step reasoning tasks. Before CoT, LLMs struggled with structured problem-solving—while they possessed vast knowledge, they lacked a systematic approach to apply it effectively to complex problems.
Why Chain-of-Thought Prompting Works:
- Mimics Human Cognitive Processes: CoT encourages LLMs to break down problems into sequential steps, similar to how humans analyze and solve intricate challenges.
- Improves Accuracy Across Diverse Domains: CoT has proven effective in arithmetic reasoning, logical reasoning, and commonsense understanding, enabling LLMs to reason through multi-step solutions rather than guessing.
In practice, CoT prompting involves giving models structured examples that illustrate reasoning steps. For instance, when addressing a mathematical word problem, the model doesn’t rush to the answer; rather, it undergoes a systematic thought process: identifying variables, establishing relationships, performing calculations, and reaching a final solution.
The influence of CoT on LLM performance has been significant. Latest reasoning-focused models, including OpenAI’s o1, DeepSeek’s R1, and Alibaba’s QwQ, have adopted CoT principles, reaching remarkable outcomes on benchmarks designed to evaluate complex reasoning. This achievement has established CoT as the standard for deriving structured reasoning from LLMs.
The Limitations of CoT:
While CoT significantly enhances reasoning, it comes at a substantial cost:
- Token Explosion: CoT increases token consumption—sometimes by an order of magnitude compared to direct prompting. More reasoning steps mean longer outputs, driving up inference costs.
- Slower Response Times: Generating and processing verbose step-by-step explanations introduces significant latency, making CoT impractical for real-time applications that require quick responses.
- High Computational Overhead: Because commercial LLM APIs charge based on token usage, CoT dramatically raises inference costs for enterprises running large-scale AI systems.
The latency implications of CoT are particularly concerning. Research by Xu et al. demonstrated that models using CoT consistently exhibited higher latency than direct prompting methods. This delay is a major drawback for real-time applications like customer support chatbots, AI tutoring systems, and live decision-making tools.
Furthermore, the cost implications of CoT extend beyond latency and token consumption; they also affect operational expenses at scale. Businesses deploying CoT-based solutions encounter significant financial burdens due to the vast number of tokens needed for structured reasoning. As CoT models become more sophisticated, this computational demand increases, rendering large-scale deployment financially unsustainable for many enterprises.
These limitations have motivated researchers to explore alternative approaches that maintain CoT’s reasoning benefits while significantly lowering its computational footprint—paving the way for Chain of Draft (CoD) prompting.
Introducing Chain of Draft (CoD) Prompting
The inception of Chain of Draft (CoD) prompting stems from a fundamental observation about human problem-solving behavior. When humans tackle complex problems—whether solving equations, drafting essays, or writing code—we rarely articulate every detail of our thought process. Instead, we use concise notes, shorthand, and minimal drafts that capture only the essential insights needed to make progress.
These abbreviated thought externalities serve as cognitive scaffolding, allowing us to track key information while minimizing mental load.
This contrast between human efficiency and the verbose nature of CoT led researchers to ask: Could LLMs adopt a similarly minimalist approach to reasoning? Their findings confirm that they can—with CoD.
Why Chain of Draft LLM prompting is a significant shift:
- Enhanced Reasoning Efficiency – Rather than simply shortening responses, CoD restructures how LLMs process and represent their reasoning, focusing on essential steps without unnecessary elaboration.
- Compact & High-Value Output – Each reasoning step is condensed so that every token carries maximum semantic meaning, ensuring efficient communication of thought.
- Clarity Without Redundancy – CoD removes unnecessary repetition while maintaining logical structure, allowing models to reason effectively while minimizing computational overhead.
For example, rather than explaining:
“To find how many lollipops Jason gave to Denny, I need to subtract the remaining lollipops from the initial number, so I calculate 20 – 12 = 8.”
CoD outputs:
“20 – 12 = 8.”
This minimalist representation retains all computational value but dramatically reduces token usage.
By prioritizing efficiency while maintaining reasoning depth, CoD directly tackles the latency and cost issues that make CoT impractical for large-scale deployment. Most importantly, CoD achieves this without requiring fine-tuning or architectural modifications, making it an accessible and practical strategy for optimizing LLM performance.
How Chain of Draft LLM Prompting Works

To understand the mechanics of Chain of Draft (CoD) prompting, let’s examine how it differs from other prompting approaches through a simple example from the original research. Consider the following arithmetic problem:
Q: Jason had 20 lollipops. He gave Denny some lollipops. Now Jason has 12 lollipops. How many lollipops did Jason give to Denny?
Comparing Prompting Strategies
Standard Prompting
With standard prompting, the LLM directly produces an answer without showing its reasoning:
Q: Jason had 20 lollipops. He gave Denny some lollipops. Now Jason has 12 lollipops. How many lollipops did Jason give to Denny?
A: 8While this approach is token-efficient, it lacks transparency. We can’t see how the model arrived at its answer, which makes it difficult to verify correctness or identify reasoning errors. This black-box nature significantly limits reliability, especially for complex problems where step-by-step reasoning is critical.
Chain-of-Thought (CoT) Prompting
With CoT prompting, the model provides detailed reasoning:
Q: Jason had 20 lollipops. He gave Denny some lollipops. Now Jason has 12 lollipops. How many lollipops did Jason give to Denny?
A: Let’s think through this step by step:
1) Initially, Jason had 20 lollipops.
2) After giving some to Denny, Jason now has 12 lollipops.
3) To find out how many lollipops Jason gave to Denny, we need to calculate the difference between the initial number of lollipops and the remaining number.
4) We can set up a simple subtraction problem: Initial number of lollipops – Remaining number of lollipops = Lollipops given to Denny
5) Putting in the numbers: 20 – 12 = Lollipops given to Denny
6) Solving the subtraction: 20 – 12 = 8
7) #### 8This response is comprehensive and transparent, showing each step of the reasoning process. However, it is unnecessarily verbose, containing repetitive information that adds no computational value. This verbosity significantly increases token usage, leading to higher latency and cost.
Chain of Draft (CoD) Prompting
With CoD prompting, the model provides only the essential reasoning:
Q: Jason had 20 lollipops. He gave Denny some lollipops. Now Jason has 12 lollipops. How many lollipops did Jason give to Denny?
A: 20 – x = 12; x = 20 – 12 = 8. #### 8The CoD approach distills the reasoning to its mathematical essence. It abstracts away all contextual details, focusing solely on the core calculation needed to solve the problem. This representation maintains transparency while dramatically reducing token usage.
Implementing Chain of Draft Prompting
The beauty of Chain of Draft LLM prompting lies in its simplicity and ease of implementation. It requires no model modifications, fine-tuning, or reinforcement learning—just a straightforward update to the prompt.
To implement CoD, you simply modify your system prompt to instruct the model to produce concise reasoning. The researchers used the following system prompt for their CoD experiments:
Think step by step, but only keep a minimum draft for each thinking step, with 5 words at most. Return the answer at the end of the response after a separator ####.
This instruction guides the model to maintain its step-by-step reasoning process but express each step concisely, limiting verbosity while preserving essential information.
Additionally, the researchers provided few-shot examples in their prompts to demonstrate the expected format. These examples showed how to transform verbose reasoning into concise, information-dense representations. Each few-shot example included both the original problem and a manually crafted Chain of Draft solutions, helping the model learn the desired response style.
The separator instruction (####) clearly demarcates the reasoning process and the final answer, facilitating easier extraction of the answer for downstream processing. This is an important consideration for practical applications.
What’s particularly noteworthy about Chain of Draft LLM prompting is that it can be applied to any existing language model without modification. There is no need for specialized training, changes to model architecture, or custom infrastructure. This plug-and-play nature makes CoD immediately accessible to practitioners seeking to optimize their LLM applications for efficiency and cost-effectiveness.
Experimental Results of Chain of Draft LLM Prompting

To rigorously evaluate Chain of Draft (CoD) prompting, the researchers conducted comprehensive experiments across diverse reasoning tasks, adhering to the same evaluation methodology used in the original Chain-of-Thought (CoT) paper. Their experimental design concentrated on three major categories of reasoning tasks that traditionally benefit from step-by-step reasoning:
Experimental Setup
The researchers selected benchmark datasets for each reasoning category:
- Arithmetic Reasoning: GSM8k, a challenging dataset of 8,500 grade school math problems requiring multi-step solutions.
- Commonsense Reasoning: Date understanding and sports understanding tasks from BIG-bench, testing the model’s ability to reason about temporal relationships and sports rules.
- Symbolic Reasoning: Coin flip tasks, which require tracking the state of a coin through a sequence of conditional operations.
For evaluation, the researchers employed two state-of-the-art language models:
- GPT-4o (gpt-4o-2024-08-06) from OpenAI
- Claude 3.5 Sonnet (claude-3-5-sonnet-20240620) from Anthropic
Each model was tested with three distinct prompting strategies:
- Standard Prompting: Direct answer generation without reasoning.
- Chain-of-Thought (CoT): Detailed step-by-step reasoning.
- Chain of Draft (CoD): Concise, minimal reasoning steps.
The evaluation focused on three key performance metrics:
- Accuracy: Correctness of the final answer.
- Token Usage: Number of tokens generated in the response.
- Latency: Time required to generate the complete response.
Arithmetic Reasoning Results
The GSM8k benchmark provided a rigorous test of arithmetic reasoning capabilities, requiring models to solve multi-step mathematical word problems.
- Standard Prompting:
- GPT-4o: 53.3% accuracy
- Claude 3.5 Sonnet: 64.6% accuracy
- These results highlight the limitations of direct answer generation for complex reasoning tasks.
- Chain-of-Thought (CoT) Prompting:
- GPT-4o: 95.4% accuracy
- Claude 3.5 Sonnet: 95.8% accuracy
- Substantial cost: ~200 tokens per response.
- Increased latency: 4.2s for GPT-4o, 3.1s for Claude 3.5 Sonnet.
- Chain of Draft (CoD) Prompting:
- GPT-4o: 91.1% accuracy
- Claude 3.5 Sonnet: 91.4% accuracy
- Efficiency boost: 80% reduction in token usage (~40 tokens per response).
- Latency improvements: 76.2% faster for GPT-4o, 48.4% faster for Claude 3.5 Sonnet.
Commonsense Reasoning Results
Researchers evaluated date understanding and sports understanding tasks from BIG-bench for commonsense reasoning.
- CoD not only reduced token usage and latency but outperformed CoT in accuracy for Claude 3.5 Sonnet (89.7% vs. 87.0%).
- In the sports understanding task, CoD reduced token usage from 189.4 to just 14.3 tokens—a 92.4% reduction.
- Despite this efficiency gain, CoD still maintained a higher accuracy than CoT (97.3% vs. 93.2%).
Symbolic Reasoning Results
For symbolic reasoning, the coin flip task required models to track the state of a coin across conditional operations.
- Standard Prompting: GPT-4o (73.2%), Claude 3.5 Sonnet (85.2%).
- CoT and CoD both achieved perfect 100% accuracy.
- However, CoD dramatically improved efficiency:
- GPT-4o: 16.8 tokens (vs. 52.4 for CoT, a 68% reduction).
- Claude 3.5 Sonnet: 18.9 tokens (vs. 135.3 for CoT, an 86% reduction).
Performance Summary
The experimental results reveal a consistent pattern across all reasoning tasks and models:
- Chain-of-Thought (CoT) significantly improves accuracy over Standard Prompting, confirming the value of step-by-step reasoning.
- Chain of Draft (CoD) maintains comparable or superior accuracy while using just a fraction of the tokens required by CoT.
- CoD reduces token usage by 68%–92% compared to CoT, with an average reduction of 80%.
- CoD substantially improves latency, cutting response times by 50–75%.
- The efficiency advantages of CoD are consistent across both GPT-4o and Claude 3.5 Sonnet, demonstrating the generalizability of this approach across different model architectures.
These findings confirm that CoD offers a powerful tradeoff between accuracy and efficiency, solving a major bottleneck in LLM applications.
Related Work in LLM Reasoning Optimization
The development of Chain of Draft (CoD) prompting exists within a broader ecosystem of research focused on improving LLM reasoning efficiency. Understanding this context highlights CoD’s novelty and significance.
Structured Reasoning Frameworks
Recent years have seen the emergence of specialized reasoning language models that leverage structured approaches to enhance problem-solving capabilities:
- OpenAI’s o1 model (2024): Optimized for complex reasoning tasks with extensive architectural refinements and training on reasoning-focused data.
- DeepSeek’s R1 model (2025): Uses reinforcement learning techniques to encourage robust, structured reasoning patterns.
- Alibaba’s QwQ model: Focuses on “reflecting deeply on the boundaries of the unknown”, training models to recognize knowledge gaps and adjust reasoning accordingly.
While these models achieve impressive performance on reasoning benchmarks, they still suffer from the same fundamental inefficiencies as CoT: high token consumption, increased latency, and higher computational costs. CoD complements these models by offering an efficiency-focused prompting strategy that enhances deployability in real-world applications.
Chain-of-Thought (CoT) Enhancements
Several research efforts have aimed to refine CoT by improving accuracy and robustness:
- Self-Consistency CoT (Wang et al., 2022): Generates multiple independent reasoning paths and selects the most consistent answer—improving accuracy but dramatically increasing computational cost.
- ReAct (Reasoning + Acting): Integrates tool usage into the reasoning process, allowing LLMs to query external knowledge bases. While powerful, this further increases token usage and latency.
These enhancements primarily prioritize accuracy over efficiency, making them impractical for latency-sensitive applications. CoD provides a complementary approach, maintaining structured reasoning while dramatically reducing computational overhead.
Latency Reduction Techniques
Several methods have been proposed to mitigate latency in LLM inference:
- Streaming Outputs: Generates incremental responses instead of waiting for a complete answer—improves perceived latency but does not reduce computational cost.
- Skeleton-of-Thought (SoT, Ning et al., 2023): First generates a skeletal outline of the response, then fills in details via parallel decoding—reduces latency but does not lower token usage.
- Layer-Skipping Approaches (Zhang et al., 2023): Generates low-quality draft responses at high speed and refines them in a second pass—improves efficiency but adds extra processing complexity.
Unlike these approaches, CoD directly addresses the root cause of latency: the excessive number of tokens generated in reasoning tasks. By reducing token usage by 80% on average, CoD improves latency in a way that is compatible with other speed-up techniques.
Direct Competitors to Chain of Draft
CoD’s closest alternatives are Concise Thoughts (CCoT) and Token-Budget-Aware LLM Reasoning (TALE)—both of which aim to reduce verbosity in reasoning.
- Concise Thoughts (CCoT): Uses a fixed global token budget for reasoning steps. However, different tasks require varying token budgets, making this approach less adaptable than CoD.
- TALE (Token-Budget-Aware LLM Reasoning): Dynamically estimates a global token budget based on problem complexity. While more flexible than CCoT, it requires an extra LLM call to estimate complexity, adding computational overhead.
How Chain of Draft LLM Prompting Differs:
- Per-Step Budgeting: Unlike CCoT and TALE, CoD applies token constraints at each step rather than setting a global limit.
- Dynamic Adaptability: CoD allows unlimited reasoning steps when necessary while still maintaining brevity and efficiency.
- Human-like reasoning aligns with how humans take notes, prioritizing essential information at each step rather than guessing how much detail is needed upfront.
This user-friendly method clarifies why CoD excels in brevity adherence compared to fixed-budget techniques, positioning it as a more effective solution for practical LLM applications.
While CoD builds on a rich history of LLM reasoning optimization, it provides a fundamentally different approach that directly addresses the efficiency limitations of prior methods. By balancing accuracy and token efficiency, CoD enables more scalable, cost-effective reasoning, making it a significant step forward in AI deployment.
Practical Applications of Chain of Draft LLM Prompting
The efficiency and accuracy of Chain of Draft (CoD) prompting make it ideal for applications where traditional CoT approaches are too slow or expensive. By reducing token usage by up to 92%, CoD enables faster, cost-effective AI reasoning across multiple industries.
Real-Time Customer Support
CoD balances reasoning quality with speed, allowing AI-powered support systems to:
- Generate complex troubleshooting steps with minimal delay.
- Accurately calculate refunds, policy decisions, and eligibility in real-time.
- Handle peak traffic efficiently with reduced computational overhead.
For example, a telecom support system could diagnose network issues in sub-second response times, while an e-commerce chatbot could instantly process return policies without lengthy explanations.
Mobile & Edge AI Applications
CoD improves AI viability in resource-constrained environments, such as mobile devices and IoT systems, by:
- Reducing data transfer needs for cloud-based inference.
- Minimizing battery drain from excessive computation.
- Enabling on-device reasoning, reducing reliance on cloud services.
For instance, a mobile AI tutor can provide step-by-step guidance efficiently without excessive processing demands.
Educational Tools & AI Tutors
Educational AI must balance detailed explanations with quick responses. CoD enables:
- Instant feedback on student work without unnecessary verbosity.
- Scalable tutoring systems that serve thousands of users efficiently.
- Concise, structured reasoning for learning tools in math, programming, and science.
A programming education platform could analyze student code errors and provide real-time corrective steps, reducing wait times from minutes to seconds.
Enterprise AI & High-Traffic Applications
For enterprises processing millions of AI queries daily, CoD delivers:
- 70-90% cost savings per query.
- Faster decision-making without sacrificing reasoning depth.
- Optimized AI infrastructure for large-scale deployments.
Financial services could streamline loan processing, fraud detection, and investment analysis, ensuring high-speed AI-driven insights at a fraction of the usual cost.
AI Reasoning in Resource-Constrained Environments
Beyond enterprises, CoD expands AI accessibility to regions with limited infrastructure:
- Nonprofits and humanitarian organizations can use AI-powered translation, education, and medical assistance tools.
- Small businesses gain access to enterprise-level AI without high operational costs.
- Edge computing (IoT, remote monitoring) benefits from efficient AI reasoning with minimal bandwidth use.
For example, a rural healthcare system could use CoD-powered AI to analyze symptoms and recommend treatment, ensuring cost-effective medical decision-making.
Expanding AI Accessibility Through CoD
CoD improves efficiency without sacrificing accuracy, making advanced reasoning capabilities available to various applications. Whether in high-volume enterprises or resource-limited settings, CoD facilitates faster, smarter, and more scalable AI reasoning, rendering sophisticated AI more practical than ever before.
Given these findings, it’s essential to explore how CoD benefits AI applications at scale
Advantages of Chain of Draft LLM Prompting
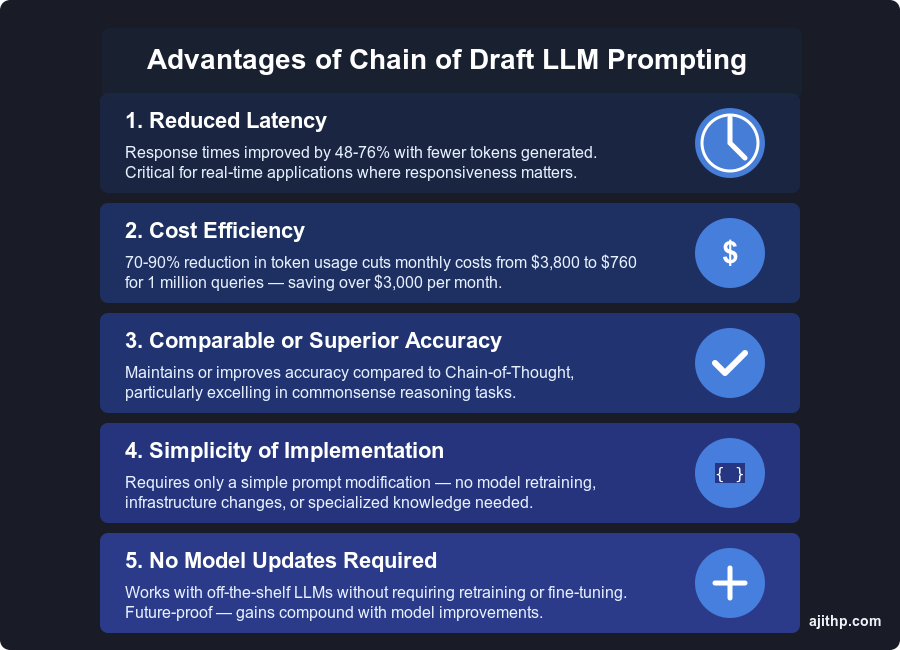
Chain of Draft (CoD) offers several key advantages that position it as a significant breakthrough in LLM reasoning. These benefits span performance, cost, and ease of adoption.
1. Reduced Latency
CoD improves response times by 48-76%, as models generate fewer tokens. This makes AI-powered applications significantly more responsive, especially in real-time support, education, and conversational AI where latency impacts user experience.
2. Cost Efficiency
By reducing token usage by 70-90% compared to CoT, CoD directly translates into lower inference costs. For an enterprise processing 1 million reasoning queries monthly, CoD could cut costs from $3,800 (CoT) to $760, saving over $3,000 per month—with even greater savings at scale. By scaling efficiently across large workloads, CoD enables enterprises to process millions of AI queries without excessive costs.
3. Comparable or Superior Accuracy
CoD achieves similar or better accuracy than CoT in many tasks. It outperforms CoT in commonsense reasoning and maintains accuracy across arithmetic and symbolic reasoning while eliminating unnecessary verbosity.
4. Simplicity of Implementation
Unlike AI techniques that require model retraining or infrastructure changes, CoD is a prompting strategy that can be adopted instantly. Organizations already using CoT can switch to CoD with a simple prompt modification, making it highly accessible. Because CoD requires no fine-tuning, enterprises can seamlessly scale AI reasoning across global deployments without model retraining.
5. No Model Updates Required
CoD works with off-the-shelf LLMs, meaning it benefits directly from new model advancements without requiring retraining or fine-tuning. This ensures future-proof efficiency gains as AI models evolve.
Related Articles
- Prompt Engineering – Unlock the Power of Generative AI
Explore the fundamentals of prompt engineering, its real-world applications, and its significance in today’s rapidly advancing AI landscape. ajithp.com - Qwen2.5-1M: The First Open-Source AI Model with a 1 Million Token Context Window
Discover how Qwen2.5-1M models can accurately retrieve hidden numbers from documents containing up to 1 million tokens, with minimal errors observed in the 7B model. ajithp.com - AI Research Agents with MLGym and MLGym-Bench
Learn about the need for advanced architectures and training algorithms to enable LLM agents to go beyond baseline improvements and contribute to scientific discovery. ajithp.com - Enhancing RAG with Multi-Agent Reinforcement Learning & MAPPO
Understand how Llama-3-8B-Instruct was chosen as the foundational LLM for MMOA-RAG due to its strong instruction-following capabilities and its ability to generate high-quality text. ajithp.com - Test Time Compute in AI: Enhancing Real-Time Inference and Adaptive Reasoning
Dive into how Test Time computing is emerging as an important approach, prompting a rethink on enhancing machine reasoning beyond scaling up computational power.
Conclusion
Chain of Draft LLM prompting has potential to play a key role in AI reasoning, making sophisticated LLM applications more practical and efficient.
The Importance of Latency Reduction
CoD directly addresses one of the biggest challenges in LLM deployment—latency. Research shows that perceived responsiveness significantly impacts user experience, with delays exceeding 1-second interrupting cognitive flow. CoD’s ability to reduce response times from multiple seconds to a fraction of a second makes it a game-changer for real-time AI interactions, education, and enterprise applications.
Challenging Assumptions About Verbosity
The success of CoD challenges the assumption that detailed articulation of reasoning steps is always necessary. The findings suggest that concise, information-dense reasoning can improve model efficiency while maintaining accuracy. This aligns with human cognitive processes, which rely on mental shortcuts, abstraction, and compressed reasoning rather than excessive detail.
Future Directions for Chain of Draft LLM Prompting
The success of CoD opens up exciting research directions, including:
- Hybrid Approaches: Combining CoD with techniques like parallel decoding or Skeleton-of-Thought for even faster inference.
- Training on Concise Reasoning: Developing LLMs specifically trained on efficient reasoning patterns.
- Task-Specific Optimization: Exploring how different reasoning tasks benefit from different brevity levels.
- Multimodal Applications: Extending CoD to text+visual reasoning models, making multimodal AI more efficient.
Implications for LLM Development
CoD’s success suggests a new direction for AI model training and evaluation:
- AI models could be optimized for reasoning efficiency alongside accuracy.
- Benchmarks might evolve to include performance-per-token metrics.
- AI reasoning could shift toward more structured, symbolic approaches that capture essential reasoning content without unnecessary language overhead.
Bridging Research & Practical AI Applications
While much of AI research focuses on pushing capability boundaries, CoD is a rare breakthrough that enhances both capability and efficiency. By offering a cost-effective, scalable alternative to CoT, CoD makes advanced reasoning practical for businesses, developers, and enterprises alike.
Final Thoughts
As AI models continue to evolve, optimizing reasoning efficiency will be as critical as improving their raw capabilities. With its ability to bridge cutting-edge AI research with practical deployment needs, CoD represents a major step toward more intelligent, efficient, and scalable AI-powered decision-making
Key Links
Research Paper: Chain of Draft: Thinking Faster by Writing Less
Authors: Silei Xu, Wenhao Xie, Lingxiao Zhao, Pengcheng He
Discover more from Ajith Vallath Prabhakar
Subscribe to get the latest posts sent to your email.
You must be logged in to post a comment.