Audio Overview
What if AI-generated answers were always accurate? Large Language Models (LLMs) have revolutionized natural language processing, enabling applications ranging from AI-powered chatbots to knowledge retrieval systems. However, these models often generate outdated or hallucinated responses due to their static training data. Retrieval-augmented generation (RAG) enhances LLMs by incorporating external knowledge, yet optimizing the complex RAG pipeline remains challenging.
Traditional approaches optimize RAG components separately, leading to inefficiencies and misaligned objectives.
A new approach, the Multi-Module joint Optimization Algorithm for RAG (MMOA-RAG), utilizes Multi-Agent Reinforcement Learning (MARL) to optimize all components simultaneously. This article examines the challenges of RAG optimization and how MMOA-RAG significantly enhances accuracy through collaborative learning.
The Challenge: Optimizing RAG Systems
Ideal RAG systems consist of multiple interdependent modules:
- Query Rewriting: Reformulates user queries to enhance retrieval quality by making them more structured and relevant.
For instance, If a user asks, “What are the latest advancements in quantum computing research?” the rewriter might transform it into “Recent breakthroughs and discoveries in quantum computing” to improve document retrieval accuracy. - Document Retrieval Retrieves relevant information from external sources such as databases, search engines, or vector-based knowledge systems.
For instance, in a customer service AI, retrieving past user complaints and resolutions from a helpdesk knowledge base ensures personalized and accurate responses. - Document Filtering: Select the most useful documents from the retrieved pool. This module scores documents based on relevance, novelty, and conciseness, removing duplicates or less informative entries.
For example, if a user asks, “What are the health benefits of green tea?” the filtering module might prioritize a recent meta-analysis over older studies or articles focusing on general beverage trends. - Answer Generation: This generator synthesizes responses based on the filtered documents. It leverages an LLM to produce coherent, factual, and contextually accurate answers.
For example, if asked about “the impact of social media on political discourse,” the generator synthesizes information from academic studies, news articles, and social media analyses to form a well-rounded response.
Most optimization techniques currently treat these modules independently, relying on supervised fine-tuning (SFT). However, this method creates a disconnect between module-specific goals and the final objective—producing the most accurate and contextually appropriate response. Some research has examined the use of reinforcement learning (RL) to enhance RAG. Still, these approaches often focus on simplistic pipelines, optimizing only one or two components at a time. MMOA-RAG redefines this paradigm by treating the entire RAG pipeline as a multi-agent system, where each module is an RL agent working towards a common goal.
MMOA-RAG Framework & Multi-Agent Reinforcement Learning
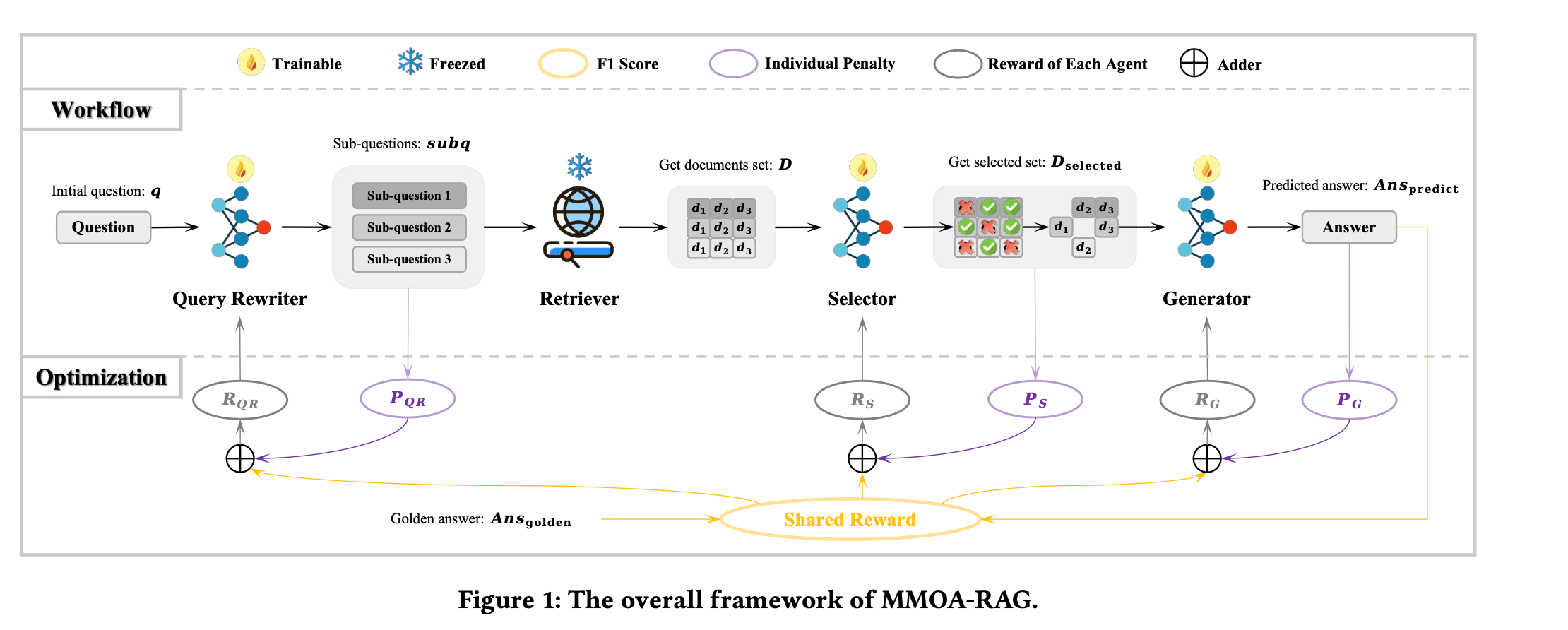
MMOA-RAG models the RAG system as a Cooperative Multi-Agent Reinforcement Learning (Co-MARL) problem, where multiple agents collaborate within the same environment to maximize a shared objective. This framework is defined formally by the tuple ⟨G, O, A, R⟩:
- G (Global State): The entire system’s current state, including query embeddings, retrieved documents, and context.
- O (Observations): Each agent receives a partial observation of G, which is relevant to its specific task. For instance, the Document Selector observes document relevance scores and semantic similarity to the query.
- A (Actions): Each agent takes actions based on observation to improve query reformulation, document selection, or response generation.
- R (Rewards): Agents receive a shared reward function based on the final output’s F1 score, ensuring alignment towards a common goal.
This cooperative setup prevents agents from working at cross-purposes and ensures their goals are aligned toward maximizing answer quality.
MAPPO Algorithm and Training Details
What is Proximal Policy Optimization (PPO)?
Proximal Policy Optimization (PPO) is a reinforcement learning algorithm that balances exploration and exploitationwhile maintaining stability in policy updates. It prevents drastic updates using a clipped objective function, ensuring policies improve gradually without catastrophic failures.
How MAPPO Extends PPO for Multi-Agent Systems
MMOA-RAG employs Multi-Agent Proximal Policy Optimization (MAPPO), an extension of PPO designed for multi-agent environments. Unlike standard PPO, which optimizes a single agent’s policy, MAPPO handles multiple agents interacting within a shared environment.
MAPPO differs from standard PPO in several key ways:
- Global Critic Model: A centralized critic evaluates the actions of all agents, ensuring that each agent’s decision contributes to a cohesive, globally optimized policy.
- Shared Reward Mechanism: Unlike independent agents that optimize separately, MAPPO ensures that all agents work towards maximizing a shared objective, such as the final answer’s F1 score.
- Simultaneous Multi-Agent Training: Instead of optimizing modules separately, MAPPO allows all RAG components to be optimized jointly, ensuring that they complement rather than contradict each other.
This cooperative training strategy ensures that each RAG component is fine-tuned to effectively contribute to the final optimized response, leading to a more accurate and contextually aligned AI-generated answer.
MAPPO Training Pseudocode
for iteration in range(num_iterations):
for agent in agents:
state = observe_environment(agent) # Get the current state of the agent
action = agent.policy(state) # Select action based on policy
reward, next_state = environment.step(action) # Execute action & get reward
agent.memory.store(state, action, reward, next_state) # Store experience
for agent in agents:
batch = agent.memory.sample() # Sample past experiences for training
advantage = compute_advantage(batch) # Compute advantage function using GAE
loss = compute_clipped_loss(advantage, agent.policy) # Prevent large updates
agent.optimizer.step(loss) # Update policy based on loss
This promotes stable multi-agent learning, whereated, enhancing end-to-end performance. policies evolve and are coordin
Detailed Agent Configurations
Each agent in MMOA-RAG has a unique role and configuration:
Query Rewriter
- Action-Space: Reformulates queries by restructuring, adding keywords, or expanding them with contextual information.
- Observation-Space: Receives the initial user query, embedded as a vector, and feedback on retrieval performance based on its previous reformulations.
- Example Decision: Expanding “impact of climate change” to “impact of climate change on global food security and agricultural yields in the 21st century.”
Document Selector
- Action-Space: Select the top-k ranked documents based on relevance scores and other criteria like diversity and information gain.
- Observation-Space: Analyzes document metadata (e.g., publication date, source), semantic similarity to the query, and redundancy with other selected documents.
- Example Decision: Prioritizing a recent report from the United Nations Food and Agriculture Organization (FAO) on climate change and agriculture over a less relevant blog post on general farming practices.
Answer Generator
- Action-Space: Synthesizes a comprehensive and informative response using the knowledge extracted from the selected documents.
- Observation-Space: Considers the user’s query, key insights and facts extracted from the selected documents, and the overall structure and flow of the information.
- Example Decision: When answering a query about “the history of artificial intelligence,” the generator might prioritize information from a seminal research paper on AI development over a general news article on recent AI applications.
Supervised Fine-Tuning (SFT) Warm Start
Before reinforcement learning, MMOA-RAG undergoes Supervised Fine-Tuning (SFT) to initialize agents with a strong baseline and improve training stability. SFT is applied to:
- Query Rewriter: Trained on a dataset of queries paired with effective reformulations, learning to improve retrieval performance.
- Document Selector: Optimized on labeled data with relevance scores for documents given specific queries, learning to identify high-quality information sources.
- Answer Generator: Fine-tuned using ground-truth question-answer pairs, learning to generate accurate and relevant responses based on given information.
SFT ensures that reinforcement learning starts with well-calibrated policies, reducing training instability and fostering faster convergence.
Multi-Agent Learning & Optimization Details
To ensure stable training and efficient collaboration, MMOA-RAG introduces:
Penalty Terms: Stabilization penalties are applied when agents deviate significantly from optimal behaviors, discouraging actions that hinder overall performance.
For example, the Query Rewriter might be penalized for generating overly complex or irrelevant reformulations. Here are specific examples of penalty terms for each agent:
Query Rewriter:
- Penalize if the cosine similarity between the embedding of the rewritten query and the original query is below a certain threshold, ensuring that the rewritten query remains semantically similar to the user’s intent.
- Penalize if the length of the rewritten query exceeds a predefined limit, preventing overly verbose or complex reformulations.
Document Selector:
- Penalize if the average pairwise Jaccard similarity between the selected documents is above a certain threshold, encouraging the selection of diverse documents with minimal redundancy.
- Penalize if the average relevance score of the selected documents is below a certain threshold, ensuring that only highly relevant documents are chosen.
Answer Generator:
- Penalize if the generated answer contains information not present in the selected documents, discouraging hallucinations or irrelevant responses.
- Penalize if the fluency or coherence of the generated answer is below a certain threshold, as determined by a language model or metric, ensuring high-quality and readable responses.
- Penalize if the generated answer exceeds a predefined length limit, promoting conciseness and preventing overly verbose responses.
Gradient Synchronization:
Ensuring that policy updates are aligned across agents is crucial for preventing conflicting optimizations and promoting collaborative learning. MMOA-RAG achieves this through parameter sharing, where all agents share the same underlying Large Language Model (LLM). This approach ensures that policy updates are consistent across agents, facilitating collaborative learning and cohesive strategy development. Research indicates that parameter sharing can significantly enhance learning efficiency in multi-agent systems.
These mechanisms allow MMOA-RAG to achieve better convergence and improve agent collaboration, leading to more effective Retrieval-Augmented Generation (RAG) performance. The shared reward function, based on the final answer’s F1 score, is a critical aspect of MMOA-RAG. It encourages cooperation among agents by aligning their objectives towards a common goal, preventing agents from pursuing individual goals that might conflict with the overall objective of generating accurate and relevant answers.
Llama-3-8B-Instruct was chosen as the foundational LLM for MMOA-RAG due to its strong instruction-following capabilities and its ability to generate high-quality text. These characteristics make it well-suited for the various tasks involved in the RAG pipeline, such as query rewriting, document selection, and answer generation.
Experimental Evaluation and Benchmark Comparisons
Datasets Used for Evaluation
- HotpotQA: A multi-hop question answering dataset requiring reasoning over multiple documents to answer complex questions.
- 2WikiMultihopQA: A dataset focused on complex document-based reasoning, where answers must be derived from multiple Wikipedia articles.
- AmbigQA: A single-hop ambiguous question dataset designed to evaluate the ability of models to handle questions with multiple possible interpretations.
Key Findings
Comparisons with Other Methods
| Method | Optimization Approach | Performance |
|---|---|---|
| SELF-RAG | Self-supervised learning | Lower retrieval accuracy |
| RetRobust | Heuristic-based retrieval | Limited generalization |
| MMOA-RAG (Ours) | Multi-agent RL (MAPPO) | State-of-the-art results |
This highlights MMOA-RAG’s superior optimization strategy, balancing retrieval precision and response accuracy across diverse datasets.
Ablation Studies
Experiments showed that removing any agent (e.g., disabling query rewriting or document selection) resulted in significant drops in F1 scores across all datasets, confirming the effectiveness of multi-agent collaboration in MMOA-RAG.
Conclusion & Future Directions
MMOA-RAG introduces a transformative approach to Retrieval-Augmented Generation through the use of multi-agent cooperative reinforcement learning. By harmonizing the goals of query rewriting, document selection, and answer generation, MMOA-RAG greatly enhances the accuracy and reliability of responses for a variety of question-answering tasks.
Key Takeaways:
- Mathematical modeling of Co-MARL ensures coordinated learning among multiple agents in the RAG pipeline.
- MAPPO training with a global critic optimizes multi-agent collaboration, leading to more effective joint policies.
- Supervised Fine-Tuning (SFT) stabilizes reinforcement learning, improving training efficiency and overall performance.
- Experimental results confirm MMOA-RAG’s superior accuracy, robustness, and generalization capabilities compared to existing methods.
Future work will explore dynamic reward shaping to enhance agent collaboration further and address more complex scenarios like multi-turn question answering, where responses are generated over multiple interactions with the user. In addition to dynamic reward shaping and multi-turn question answering, future research directions for MMOA-RAG include:
- Exploration of Different Reward Functions: Investigate alternative reward functions that incorporate additional factors, such as answer conciseness, information gain, or user satisfaction, to optimize the RAG system’s performance further.
- Integration with More Complex RAG Architectures: Explore the applicability of MMOA-RAG to more complex RAG architectures, such as those incorporating knowledge graphs or reasoning modules, to enhance the system’s capabilities.
- Application to Other NLP Tasks: Investigate the potential of MMOA-RAG for other NLP tasks beyond question answering, such as text summarization, dialogue generation, or machine translation, where multi-agent collaboration could improve performance.
Related Articles:
- Enhancing AI Accuracy: From Retrieval-Augmented Generation (RAG) to Retrieval Interleaved Generation (RIG) with Google’s DataGemma
- RARE: Enhancing AI Accuracy in High-Stakes Question Answering
- Beyond Traditional RAG: LongRAG’s Innovative Approach to AI-Powered Information Retrieval and Generation
Key Links:
Multi-Agent Reinforcement Learning
Research Paper: Improving Retrieval-Augmented Generation through
Authors: Yiqun Chen, Lingyong Yan, Weiwei Sun, Xinyu Ma, Yi Zhang, Shuaiqiang Wang, Dawei Yin, Yiming Yang, Jiaxin Mao
GitHub Link: https://github.com/chenyiqun/MMOA-RAG
Discover more from Ajith Vallath Prabhakar
Subscribe to get the latest posts sent to your email.
You must be logged in to post a comment.