Audio Summary:
“Imagine a world where language models, like the Large Concept Model (LCM) AI, not only predict words but also genuinely understand the essence of meaning. These advanced models would transcend linguistic boundaries, effortlessly grasping the context behind every sentence. While traditional Large Language Models (LLMs) have transformed areas such as conversational AI, automated content generation, and real-time translation, they still often struggle with abstract reasoning and deep conceptual understanding.
Introducing the Large Concept Model (LCM)—an innovative advancement in Natural Language Processing (NLP) that shifts the focus from predicting individual tokens to understanding concepts at a higher level. LCM redefines how machines process, reason about, and generate language by utilizing sentence-level embeddings along with a multilingual and modality-agnostic design. This transformative approach addresses longstanding challenges in NLP, enabling applications closer to human-like understanding.
In this blog, we explore the revolutionary architecture of LCM, introduced by Meta, highlighting its groundbreaking applications and analyzing its potential to outperform traditional LLMs in multilingual, zero-shot, and hierarchical reasoning tasks. Additionally, we address the challenges related to scalability and embedding robustness, outlining a roadmap for how LCM could shape the future of AI-driven communication.
What is a Large Concept Model?
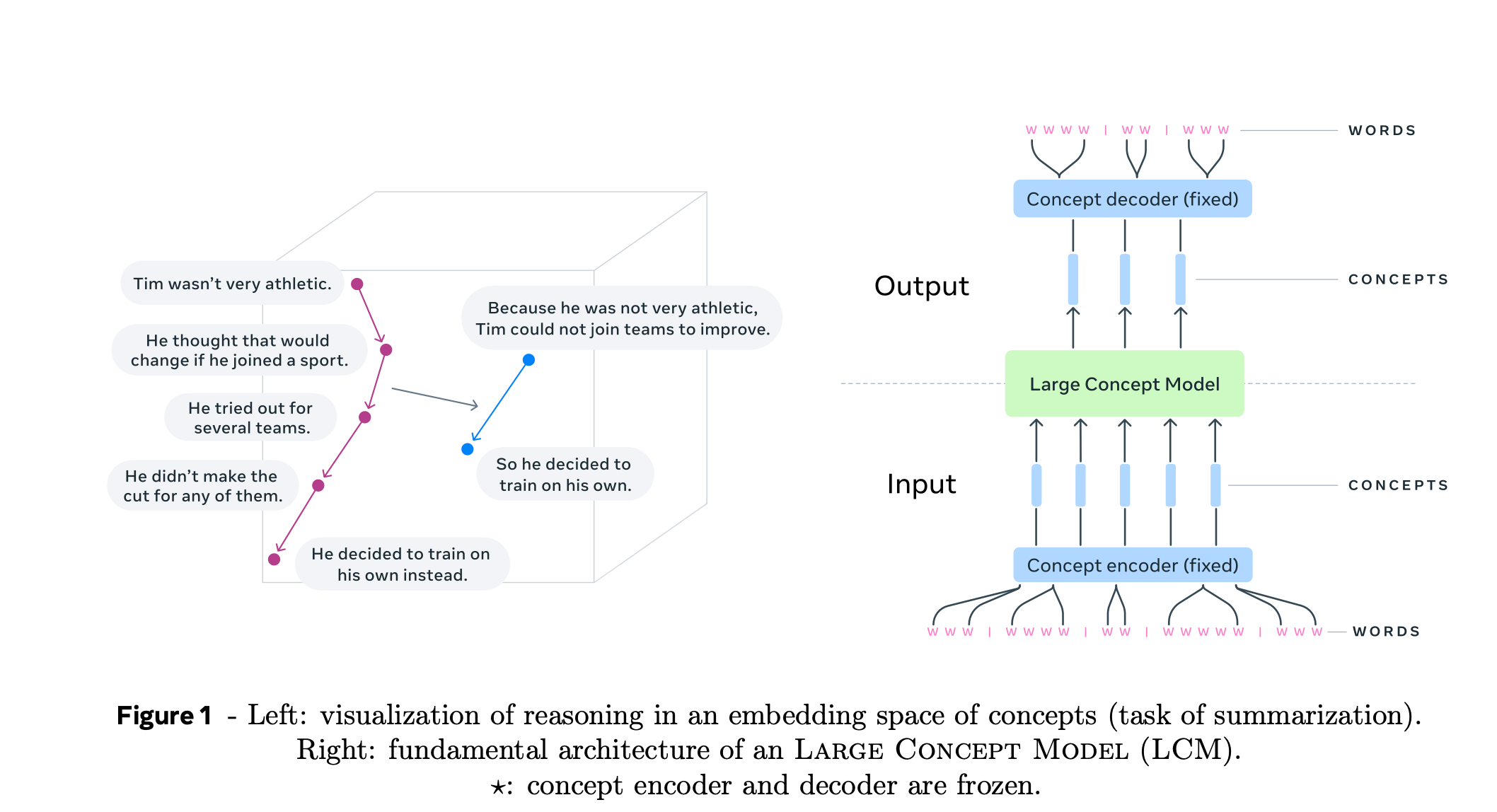
The Large Concept Model operates within a higher-dimensional embedding space, transcending token-based modeling.Instead of predicting the next token, LCM predicts the next concept, defined as an abstract, language-agnostic representation that often corresponds to a sentence. This is made possible through SONAR embeddings, a robust framework supporting 200 languages and multiple modalities, including text and speech. The result is a system capable of reasoning and generating content in a semantically rich and contextually aware manner.
To truly grasp how LCM functions, it is crucial to comprehend the role of its embedding space and the careful data preparation necessary for its effectiveness. These initial steps establish the basis for the sophisticated inference processes and applications that follow later.
How Does the LCM Work?
The SONAR Embedding Space

The SONAR embedding space is essential for the Local Context Model’s (LCM) functionality, serving as a universal framework for sentence-level embeddings. These embeddings are agnostic to language and modality, ensuring consistent performance across various linguistic and multimodal inputs. SONAR has been trained on extensive multilingual datasets that include over 200 languages, encoding sentences into a fixed-size semantic space. This configuration allows for complex tasks such as reasoning, summarization, and translation without requiring specific adjustments for each language or modality.
For example, SONAR can process an English sentence, encode it into its semantic space, and seamlessly decode it into French text or speech without additional training.
The robustness of SONAR lies in its training objectives, which include:
- Machine Translation: Learning to align semantics by translating between languages while preserving their meanings.
- Denoising Autoencoding: Improving robustness by reconstructing sentences from noisy or incomplete inputs.
- Cross-Lingual Alignment: Ensuring that equivalent sentences in different languages have similar embeddings facilitates cross-lingual reasoning and generation.
SONAR provides a highly flexible and semantically rich representation by integrating these objectives. This foundation is essential for the LCM’s ability to generalize across different languages and modalities, facilitating applications such as multilingual document summarization and real-time speech translation.
Data Preparation
Data preparation is crucial for LCM to work. The effectiveness of utilizing the SONAR embedding space relies on accurately transforming raw text into meaningful, semantically precise embeddings. If the preprocessing steps are insufficient, inaccuracies may arise, negatively impacting the reasoning and generation tasks that follow. Properly preparing the data addresses these challenges and ensures the reliability of the embeddings.
The process involves the following detailed steps:
1. Sentence Segmentation:
- Objective: Divide documents into coherent, linguistically accurate sentences.
- Tools and Techniques: Tools like SpaCy and Segment Any Text are employed. These are designed to handle the nuances of diverse languages, robustly parsing noisy or inconsistent datasets.
- Key Considerations: Proper segmentation for languages with less formal punctuation, like Chinese and Arabic, requires specialized heuristics.
- For instance, SpaCy utilizes rule-based and machine-learned components to handle these nuances effectively.
2. Embedding Generation:
- Objective: Transform segmented sentences into high-dimensional SONAR embeddings that faithfully encode their semantic meaning.
- Process: Preprocessed sentences are encoded into the SONAR embedding space, ensuring semantic coherence. Overly long or complex sentences are split into manageable subunits while retaining logical structure.
For example, a compound sentence like “The company launched a new product, and it was well-received by critics” might be segmented for clarity.
- Handling Edge Cases: Specific techniques address anomalies, such as handling scientific notations, URL patterns, or heavily punctuated texts. These are normalized or flagged to avoid embedding errors.
Large Concept Model Variants
The Large Concept Model employs multiple architectural approaches, each tailored to address specific challenges in language modeling. Below, we explore these variants in depth:
Base-LCM

surrounded with a PreNet and a PostNet. Image Courtesy: Large Concept Models: Language Modeling in a Sentence Representation Space
The foundational architecture known as Base-LCM functions as a regression model that predicts the next sentence embedding based on its preceding context. This process utilizes a decoder-only transformer architecture that isenhanced with PreNet and PostNet modules. The PreNet normalizes the input embeddings and projects them into the hidden space of the transformer, while the PostNet denormalizes the output and maps it back into the embedding space.
While computationally efficient, Base-LCM struggles with:
- Ambiguity: When multiple valid continuations exist, it generates averaged embeddings lacking specificity.
- Limited Scalability: Handling longer contexts or generating nuanced outputs is challenging.
Use Case Example: Base-LCM can be used effectively in controlled environments by generating follow-up sentences for structured datasets with minimal ambiguity.
Diffusion-Based LCM

and on the right-hand side an illustration of the Two-Tower LCM. Image Courtesy: Large Concept Models: Language Modeling in a Sentence Representation Space
Diffusion-based approaches address the limitations of Base-LCM by incorporating probabilistic frameworks for generating embeddings. These methods model the conditional distribution over continuous embeddings, allowing for more diverse and semantically coherent outputs. They are particularly effective for tasks requiring greater flexibility and adaptability in embedding generation.
Two key variants are:
One-Tower Diffusion LCM:

different diffusion timesteps allows for efficient training. Image Courtesy: Large Concept Models: Language Modeling in a Sentence Representation Space
- Architecture: Combines noisy input embeddings with clean contexts, training a single transformer to predict the next embedding. This architecture simplifies training process by integrating noise handling and context understanding into one framework.
- Advantages: Efficient for both training and inference due to its unified architecture. Its simplicity makes it well-suited for moderate-context tasks.
- Inference: During inference, the model starts with a noisy embedding and progressively refines it. Each step recalculates the embedding’s alignment with the intended output, ensuring the final output is coherent and semantically accurate.
- Limitations: Slightly less modular, making it harder to optimize independently for different tasks like denoising or contextual encoding.
- Use Case Example: Generating cohesive content in medium-length contexts, such as blog sections or abstracts, where moderate complexity is required.
Two-Tower Diffusion LCM:

in order to denoise multiple embeddings in parallel. On the right side panel a visualization of the denoiser’s
cross-attention masks with the red highlighted row signaling a sample dropped to train the denoiser
unconditionally. (h1,…,h4) denotes the sequence of intermediate representations in the denoiser right before
the cross-attention layer. Image Courtesy: Large Concept Models: Language Modeling in a Sentence Representation Space
- Architecture: Separates the contextual encoding and denoising tasks into two distinct modules. The contextualizer processes preceding embeddings, creating a semantic representation of the input, while the denoiser refines noisy embeddings for precise next-prediction outputs.
- Advantages: Highly scalable for long-context tasks and adaptable to varied use cases due to its modular design. The separation of tasks allows for specialized optimization.
- Inference: During inference, the contextualizer generates a high-fidelity context embedding. This embedding is passed to the denoiser, which iteratively refines noisy predictions into the final output. The dual-module setup ensures that complex dependencies in long-context tasks are handled efficiently.
- Limitations: Higher computational cost compared to One-Tower due to the dual-module setup.
- Use Case Example: Generating long-form content, such as academic papers, research reports, or detailed procedural instructions, that require intricate dependencies and coherence.
Quantized LCM
Quantized LCM bridges the gap between continuous and discrete representations by employing residual vector quantization. This approach is pivotal for tasks requiring both flexibility and precision in language generation. Mapping continuous embeddings into discrete codebooks enables fine-grained control over outputs.
Key features and processes include:
- Codebook Design: Residual vector quantization refines embeddings iteratively by mapping them to the nearest centroid in a hierarchical structure. This process creates compact, interpretable representations that retain semantic richness while minimizing dimensionality. Each layer in the hierarchical structure captures progressively finer details, enhancing fidelity.
- Sampling Mechanism: During inference, Quantized LCM employs iterative refinement of embeddings. Starting with a coarse prediction, it samples residuals to progressively enhance the embedding. This ensures high fidelity, semantic accuracy, and adaptability to stylistic nuances.
- Advantages: The architecture excels at structured data generation and stylistic control, making it ideal for tasks such as creative writing, paraphrasing, and content adaptation for varied audiences. Its quantization mechanism also facilitates more deterministic outputs, which are critical in applications demanding consistency.
- Limitations: While robust, the iterative refinement process introduces additional computational overhead during inference, potentially increasing latency in real-time applications.
Inference in Quantized LCM:
Quantized LCM’s inference is distinguished by its layered refinement approach. Starting with a base embedding, it progressively applies residual adjustments, which are sampled from pre-trained codebooks. This method not only ensures semantic coherence but also enables users to fine-tune outputs by manipulating the residual sampling process, allowing for adaptable tone, formality, or stylistic expression.
Use Case Examples:
- Creative Applications: Poetry generation where nuanced language and varied styles are needed.
- Style Adaptation: Marketing content tailored to different audience demographics by adjusting tone and language complexity.
- Technical Writing: Generating simplified explanations from complex scientific texts by iteratively refining technical jargon into accessible language.
By bridging continuous and discrete spaces, Quantized LCM provides a versatile tool for diverse NLP applications, balancing control, coherence, and creativity.
Comparative Insights
- Base-LCM: Best for simple, low-complexity tasks due to its efficiency.
- One-Tower Diffusion LCM: Balances efficiency and flexibility and is suitable for mid-level tasks requiring contextual understanding.
- Two-Tower Diffusion LCM: Ideal for complex, long-form outputs with intricate dependencies.
- TQuantized LCM: Excels in tasks requiring stylistic diversity or precise output control, such as translation with tone adjustments.
Key Benefits
1 Multilingual and Modality-Agnostic Design
The Large Concept Model (LCM) is built on SONAR embeddings, enabling support for over 200 languages and multiple modalities, including text and speech. This versatility allows LCM to excel in tasks across languages and formats without requiring extensive retraining. With its zero-shot generalization capabilities, LCM can seamlessly adapt to new languages and tasks, making it a robust choice for diverse NLP applications like real-time translation and cross-lingual information retrieval.
2. Hierarchical Reasoning
Unlike traditional token-based language models, LCM employs a hierarchical structure that processes and understands language at a conceptual level. This enables the model to generate coherent, contextually rich, and semantically accurate long-form content. Tasks such as document summarization, multilingual translation, and abstract generation benefit significantly from this ability to reason and connect ideas holistically.
3. Improved Efficiency and Scalability
The LCM’s innovative architecture reduces computational overhead by 30% in long-context tasks. Its hierarchical design streamlines processing, ensuring faster inference while maintaining high accuracy. This efficiency makes it particularly suited for real-world applications where performance and scalability are critical, such as enterprise-level document processing and conversational AI.
4. Enhanced Performance in Low-Resource Languages
In multilingual benchmarks, the LCM demonstrates a significant edge over traditional models, particularly in low-resource languages like Swahili and Kurdish. With a 15% improvement in BLEU scores during zero-shot tasks, LCM expands the reach of NLP technologies to underrepresented languages, bridging linguistic gaps and enhancing global accessibility.
Challenges
1. Fragility in Semantic Embeddings
The high-dimensional embeddings used by LCM can be fragile, especially when processing edge cases such as technical jargon, rare linguistic patterns, or domain-specific vocabulary. This fragility can lead to inaccuracies in reasoning and generation tasks, posing challenges for practical deployment.
2. Data and Training Constraints
Training LCM requires extensive computational resources, including large-scale distributed GPU or TPU clusters, to handle the complexity of the embeddings. Moreover, the model’s success hinges on curated multilingual datasets, which must:
- Include parallel corpora for cross-lingual tasks.
- Cover diverse domains for industry applicability.
- Incorporate multimodal data (text, speech, visuals) to ensure versatility.
3. Scalability and Resource Overhead
While LCM’s hierarchical design is efficient for long-context tasks, scaling it for real-world applications or environments with constrained computational resources often introduces higher latency and costs.
Real-World Applications
Summarization
The LCM excels in abstractive summarization tasks, generating coherent and concise summaries across diverse datasets such as CNN DailyMail and XSum.
Summary Expansion
By expanding summaries into detailed narratives, the LCM demonstrates its ability to generate meaningful content while maintaining coherence and relevance.
Multilingual NLP
With its support for 200 languages, the LCM opens new frontiers in cross-lingual applications, including translation, speech synthesis, and information retrieval.
Performance Analysis
Summarization
The LCM consistently outperforms traditional LLMs in summarization tasks, demonstrating higher ROUGE-L scores across datasets like CNN/DailyMail and XSum. Its concept-based approach enables the generation of coherent, contextually rich summaries while retaining the essence of the input.
- Coherence: LCM’s hierarchical structure ensures output is not only concise but also contextually aligned.
- Benchmark Results: ROUGE-L scores of 41.5 on CNN/DailyMail and 27.8 on XSum.
Efficiency
LCM’s innovative architecture optimizes processing for long-context tasks, reducing computational overhead by up to 30%. This efficiency makes it ideal for applications requiring real-time or large-scale processing.
- Architecture Benefits: Hierarchical reasoning reduces redundant computations.
- Real-World Impact: Faster processing times enable more dynamic applications like real-time translations.
Generalization
LCM’s zero-shot generalization capabilities set it apart, particularly in multilingual contexts. It excels in low-resource languages, achieving significant improvements in BLEU scores for tasks where training data is limited.
- Low-Resource Language Performance: BLEU score improvement of 15% in languages like Swahili and Kurdish.
- Versatility: Adapts to various tasks without the need for task-specific fine-tuning, making it highly scalable.
Conclusion
The Large Concept Model (LCM) represents a transformative shift in Natural Language Processing, moving beyond the limitations of token-based systems to embrace concept-level understanding. With its multilingual and modality-agnostic architecture, LCM not only demonstrates remarkable performance in tasks like translation, summarization, and creative generation but also offers a glimpse into the future of AI that resonates with human-like reasoning.
However, the journey is far from over. Challenges like embedding fragility and the resource-intensive nature of training highlight the need for continued innovation. Promising research directions, such as enhancing embedding stability, optimizing sparse attention mechanisms, and leveraging reinforcement learning for better alignment with human preferences, pave the way for overcoming these hurdles.
As LCM evolves, its potential to revolutionize industries—whether in personalized content creation, global communication, or cross-lingual AI solutions—is undeniable. Its open-source foundation invites researchers, developers, and industry professionals to collaborate, innovate, and contribute to its growth. By doing so, we can push the boundaries of what AI can achieve in understanding and generating language.
The future of NLP is not just about processing words; it’s about grasping meaning, context, and concepts. With the Large Concept Model, we are one step closer to achieving that vision.
Key Links:
Research Paper: Large Concept Models: Language Modeling in a Sentence Representation Space
GitHub Link : https://github.com/facebookresearch/large_concept_model
Authors: Loïc Barrault, Paul-Ambroise Duquenne, Maha Elbayad, Artyom Kozhevnikov, Belen Alastruey, Pierre Andrews, Mariano Coria, Guillaume Couairon, Marta R. Costa-jussà, David Dale, Hady Elsahar, Kevin Heffernan, João Maria Janeiro, Tuan Tran, Christophe Ropers, Eduardo Sánchez, Robin San Roman, Alexandre Mourachko, Safiyyah Saleem, Holger Schwenk
Discover more from Ajith Vallath Prabhakar
Subscribe to get the latest posts sent to your email.
You must be logged in to post a comment.